


TL;DR
第三次浏览器战争正在悄然展开。回顾历史,从上世纪 90 年代的 Netscape、微软的 IE,再到开源精神的 Firefox 与 Google 的 Chrome,浏览器之争一直是平台控制权与技术范式变迁的集中体现。Chrome 凭借更新速度与生态联动夺得霸主地位,而 Google 通过搜索与浏览器的“双寡头”结构,形成了信息入口的闭环。
但今天,这一格局正在动摇。大型语言模型(LLM)的崛起,使得越来越多用户在搜索结果页“零点击”完成任务,传统的网页点击行为正在减少。同时,Apple 有意在 Safari 中替换默认搜索引擎的传闻,进一步威胁 Alphabet (Google 母公司) 的利润根基,市场已开始显露出对“搜索正统”的不安。
浏览器本身也正面临角色重塑。它不仅是展示网页的工具,更是数据输入、用户行为、隐私身份等多种能力的集合容器。AI Agent 虽强,但若要完成复杂的页面交互、调用本地身份数据、控制网页元素,仍然需要借助浏览器的信任边界和功能沙盒。浏览器正在从人类界面,变成 Agent 的系统调用平台。
在本文,我们探讨了浏览器是否还有存在的必要,同时我们认为真正可能打破当前浏览器市场格局的,不是另一个“更好的 Chrome”,而是一种新的交互结构:不是信息的展示,而是任务的调用。未来浏览器要为 AI Agent 设计——不仅能读,还能写和执行。像 Browser Use 这样的项目正尝试将页面结构语义化,把可视化界面变成 LLM 可调用的结构化文本,实现页面到指令的映射,极大降低交互成本。
市面上主流项目已开始试水:Perplexity 构建原生浏览器 Comet,用 AI 代替传统搜索结果;Brave 把隐私保护与本地推理结合,用 LLM 增强搜索与屏蔽功能;而 Donut 等 Crypto 原生项目,则瞄准 AI 与链上资产交互的新入口。这些项目共同特征是:试图重构浏览器的输入端,而非美化其输出层。
对创业者而言,机遇藏在输入、结构与代理的三角关系中。浏览器作为未来 Agent 调用世界的接口,意味着谁能提供可结构化、可调用、可信任的“能力块”,谁就能成为新一代平台的组成部分。从 SEO 到 AEO(Agent Engine Optimization),从页面流量到任务链调用,产品形态与设计思维都在重构。第三次的浏览器战争,发生在“输入”而非“展示”;决定胜负的,不再是谁抓住用户的眼球,而是谁赢得了 Agent 的信任,获得调用的入口。
浏览器发展简史
在上世纪 90 年代初,互联网尚未成为日常生活的一部分时,Netscape Navigator 横空出世,如同开启新大陆的帆船,为数以百万计的用户打开了通往数字世界的大门。这款浏览器并非第一个,但却是第一个真正意义上走向大众、塑造互联网体验的产品。彼时,人们第一次能如此轻松地通过图形界面浏览网页,仿佛整个世界都突然变得触手可及。
然而,辉煌往往短暂。微软很快意识到浏览器的重要性,并决定将 Internet Explorer 强行捆绑进 Windows 操作系统,让其成为默认浏览器。这一策略堪称“平台杀手锏”,直接瓦解了 Netscape 的市场主导地位。许多用户并非主动选择 IE,而是因为系统默认便接受了它。IE 借助 Windows 的分发能力,迅速成为行业霸主,Netscape 则陷入了衰败的轨道。

Firefox Logo Evolution
在困境中,Netscape 的工程师选择了一条激进而理想主义的道路——他们将浏览器源代码公开,向开源社区发出召唤。这一决定,仿佛是一次技术界的“马其顿式让位”,预示着旧时代的终结与新力量的崛起。这段代码后来成为 Mozilla 浏览器项目的基础,最初命名为 Phoenix(意为凤凰涅槃),却因商标问题几经更名,最终定名为 Firefox。
Firefox 并非简单复制 Netscape,它在用户体验、插件生态、安全性等方面实现了多项突破。它的诞生标志着开源精神的胜利,也为整个行业注入新的活力。有人形容 Firefox 是 Netscape 的“精神继承者”,如同奥斯曼帝国继承了拜占庭的余晖。这一比喻虽夸张,却颇具意味。
但在 Firefox 正式发布前的几年,微软早已发布了六个版本的 IE,凭借时间优势和系统捆绑策略,使 Firefox 一开始便处于追赶地位,注定这场竞赛并非起跑线平等的公平竞争。
与此同时,另一个早期玩家也在悄然登场。1994 年,Opera 浏览器问世,它来自挪威,起初只是一个实验性项目。但从 2003 年的 7.0 版本起,它引入了自研的 Presto 引擎,率先支持 CSS、自适应布局、语音控制以及 Unicode 编码等前沿技术。虽然用户数量有限,但技术上始终走在行业前列,成为“极客的最爱”。
同年,苹果推出了 Safari 浏览器。这是一场别有意味的转折。彼时,微软曾向濒临破产的苹果注资 1.5 亿美元,以维持竞争表象、避免反垄断审查。虽然 Safari 从诞生起的默认搜索引擎是 Google,但这段与微软的历史纠葛象征着互联网巨头之间复杂而微妙的关系:合作与竞争,总是如影随形。
2007 年,IE 7 随 Windows Vista 推出,但市场反馈平平。反观 Firefox,凭借更快的更新节奏、更友好的扩展机制以及对开发者的天然吸引力,市场份额稳步提升至约 20% 。IE 的统治逐渐松动,风向正在改变。
谷歌则是另一种打法。虽然从 2001 年起就开始酝酿打造自家浏览器,但花了六年时间才说服 CEO 埃里克·施密特批准这个项目。Chrome 于 2008 年问世,基于 Chromium 开源项目与 Safari 所用的 WebKit 引擎打造。它被戏称为“臃肿”的浏览器,但凭借谷歌对广告投放与品牌塑造的深厚功力,迅速崛起。
Chrome 的关键武器并非功能,而是频繁的版本更新节奏(每六周一次)与全平台统一体验。2011 年 11 月,Chrome 首次超越 Firefox,市场份额达到 27% ;六个月后,又反超 IE,完成了从挑战者到主宰者的转变。
与此同时,中国的移动互联网也在形成自己的生态系统。阿里巴巴旗下的 UC 浏览器在 2010 年代初迅速蹿红,尤其是在印度、印尼、中国等新兴市场,依靠轻量级设计、压缩数据节省流量等特性,赢得了低端设备用户的青睐。2015 年,其全球移动浏览器市场份额突破 17% ,在印度一度高达 46% 。但这场胜利并不持久。随着印度政府加强对中国应用的安全审查,UC 浏览器被迫退出关键市场,逐渐失去往日辉煌。
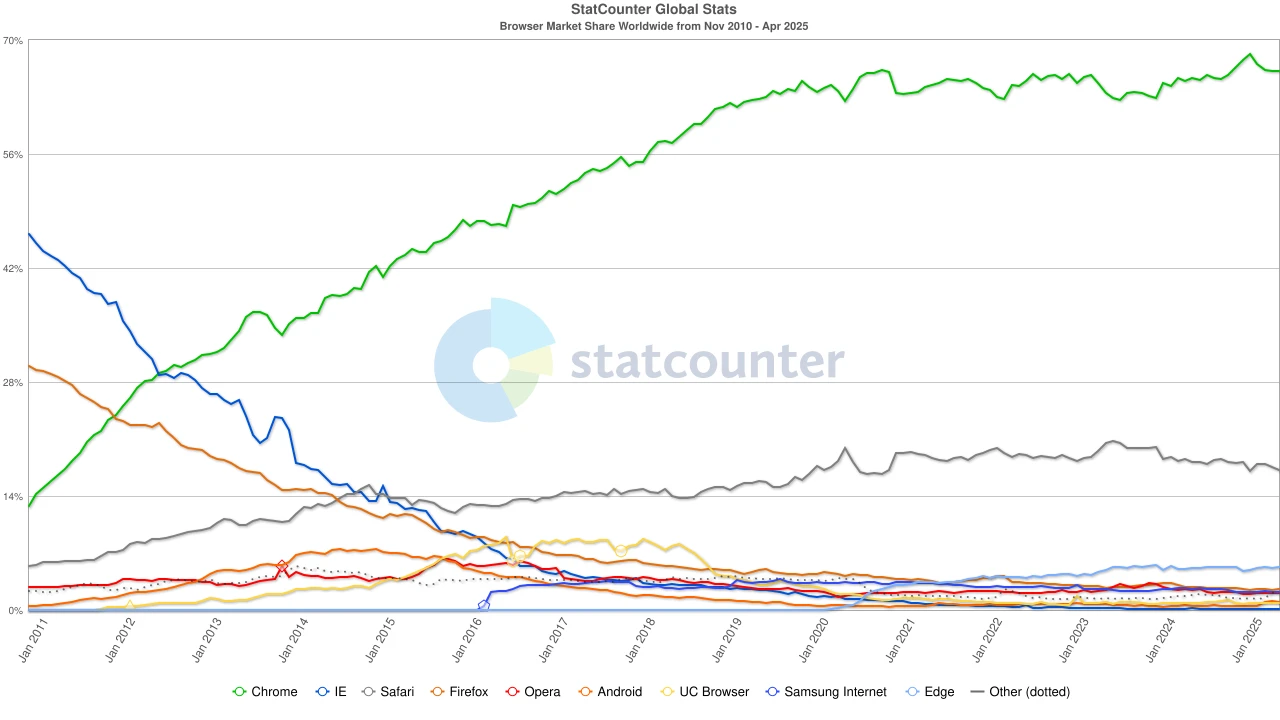
Browser market share, source: statcounter
进入 2020 年代,Chrome 的主导地位已经确立,全球市场份额稳定在约 65% 。值得注意的是,Google 搜索引擎与 Chrome 浏览器虽然同属 Alphabet,但从市场层面看却是两个独立的霸权体系——前者控制了全球约九成的搜索入口,后者则掌握了大多数用户进入网络的“第一窗口”。
为了守住这一双重垄断结构,谷歌不惜重金投入。2022 年,Alphabet 向苹果支付约 200 亿美元,只为让 Google 保持在 Safari 中的默认搜索地位。有分析指出,这笔支出相当于谷歌从 Safari 流量中获取搜索广告收入的 36% 。换言之,谷歌正为护城河支付“保护费”。
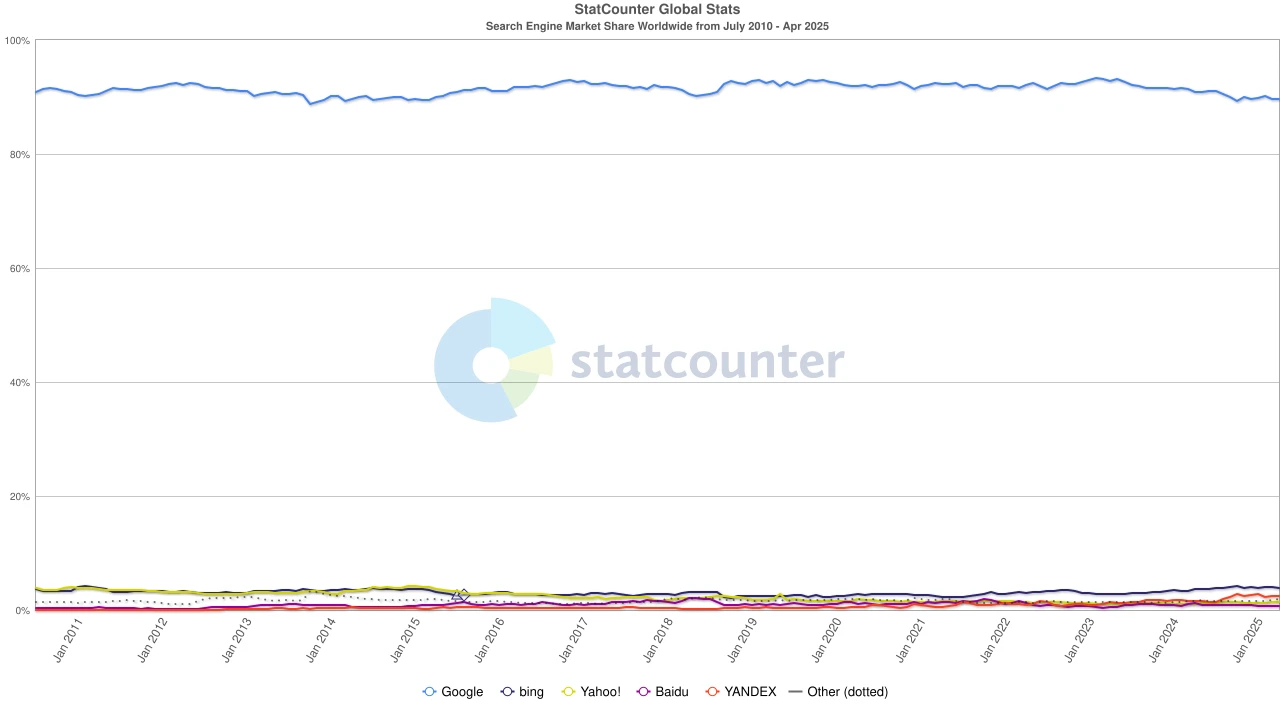
Search Engine market share, source: statcounter
但风向又一次变化。随着大型语言模型(LLM)的崛起,传统搜索开始受到冲击。2024 年,Google 的搜索市场份额自 93% 跌至 89% ,虽仍称霸,但裂痕初现。更具颠覆性的,是关于苹果或将推出自有 AI 搜索引擎的传闻——若 Safari 默认搜索改投自家阵营,这不仅将改写生态格局,更可能撼动 Alphabet 的利润支柱。市场反应迅速,Alphabet 股价从 170 美元应声下跌至 140 美元,反映的不仅是投资者的恐慌,更是对搜索时代未来走向的深度不安。
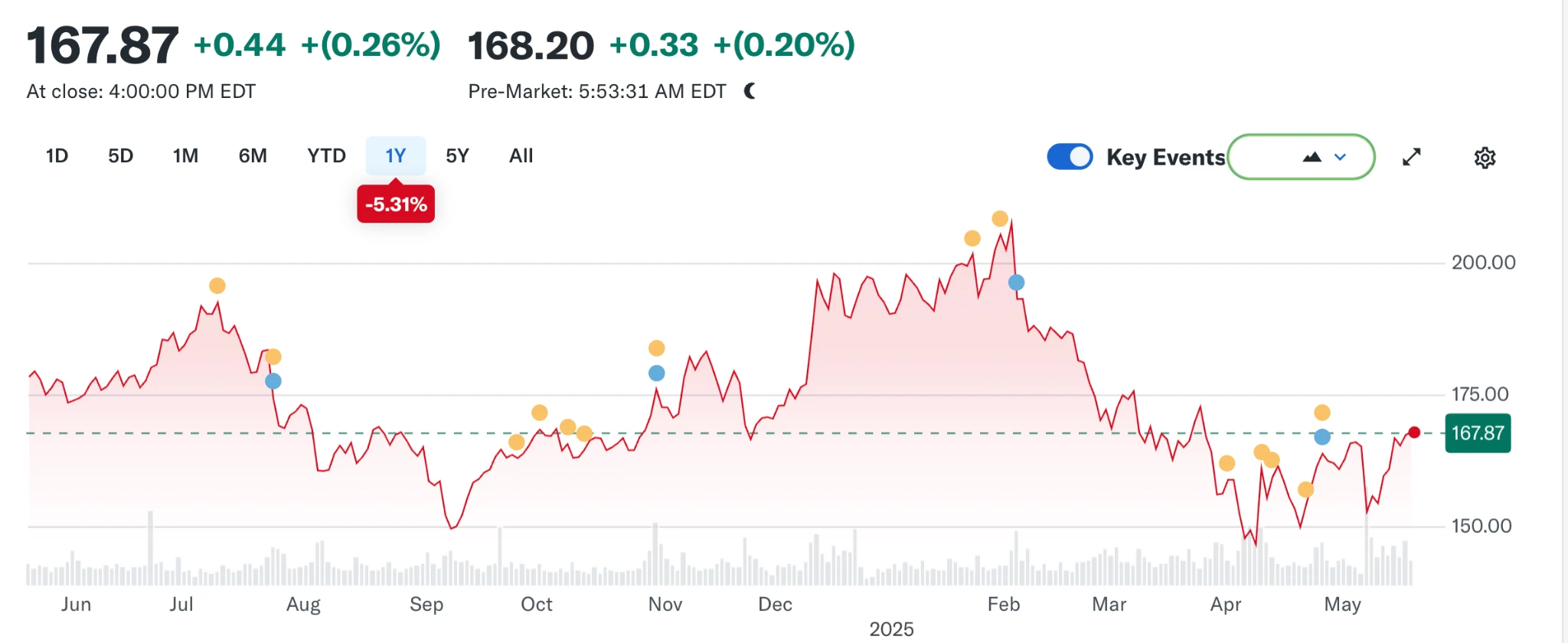
从 Navigator 到 Chrome,从开源理想到广告商业化,从轻量浏览器到 AI 搜索助手,浏览器之争始终是一场关于技术、平台、内容与控制权的战争。战场不断迁移,但本质从未改变:谁掌握入口,谁就定义未来。
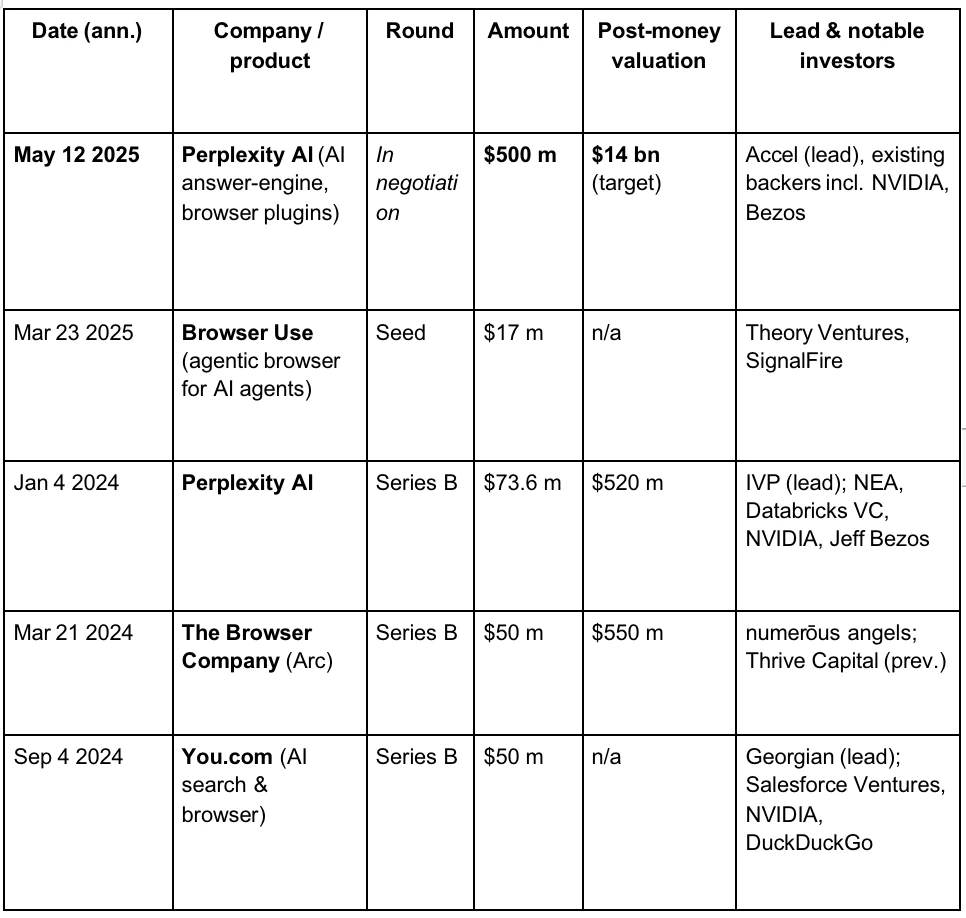
在 VC 眼中,依托 LLM 和 AI 时代人们对搜索引擎的新需求,第三次浏览器战争正在逐步展开。以下是部分知名 AI 浏览器赛道的项目的融资情况。
现代浏览器的老旧架构
谈及浏览器的架构,经典的传统架构如下图所示:
The overall architecture, source: Damien Benveniste
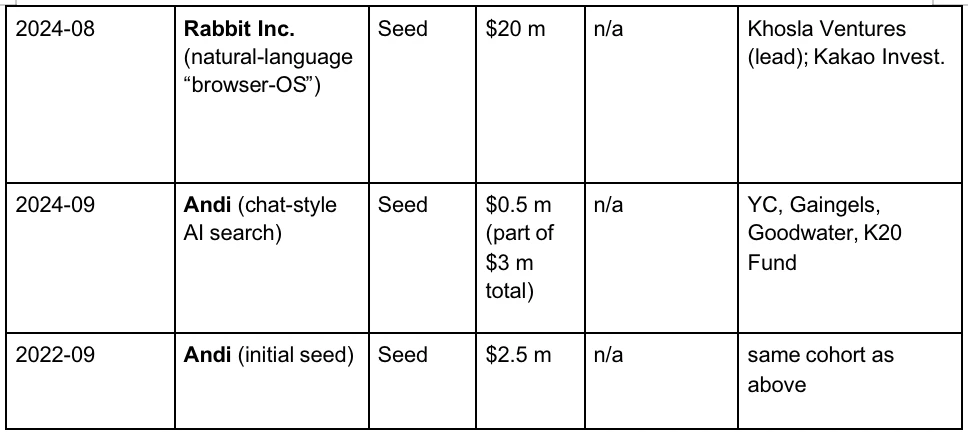
1. 客户端 - 前端入口
查询经 HTTPS 送达最近的 Google Front End,完成 TLS 解密、QoS 采样和地理路由。若检测到异常流量(DDoS、自动抓取)可在此层限流或挑战。
2. 查询理解
前端需要理解用户键入的单词的含义,有三个步骤:神经拼写校正,将 “recpie” 纠正为 “recipe”;同义词扩展,将“how to fix bike”,拓展到“repair bicycle”。意图解析,判定查询是资讯、导航还是交易意图,并分配 Vertical 请求。
3. 候选召回
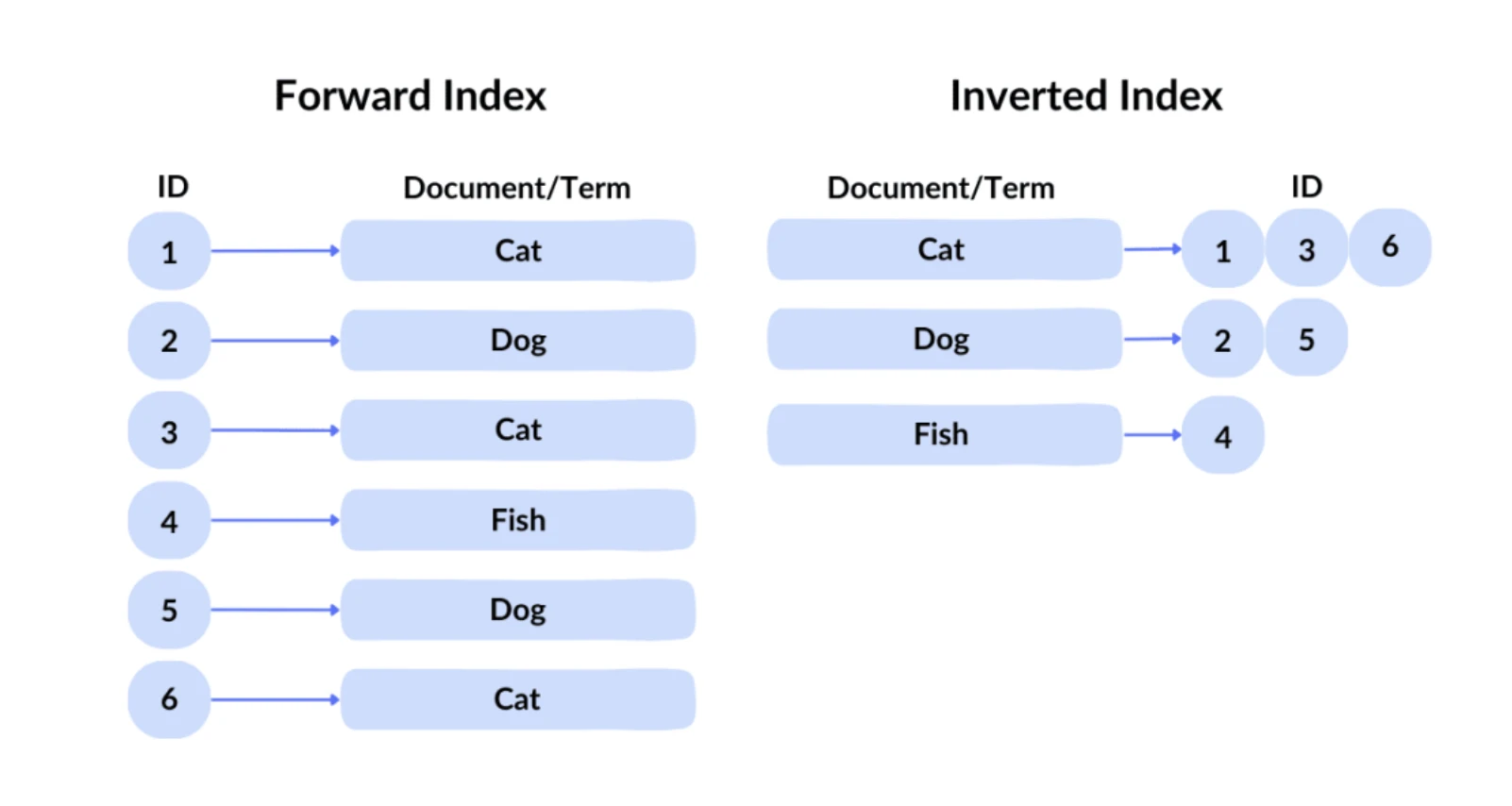
Inverted Index, source:spot intelligence
Google 使用的查询技术被称为:倒排索引。在正序索引中,我们都是给定一个 ID 就可以索引到文件。但是用户不可能知道想要的内容在上千亿个文件中的编号,因此其采用了非常传统的倒排索引,通过内容来查询到哪些文件有对应的关键字。接下来,Google 采用向量索引用于处理语义搜索,即查找与查询含义相似的内容。它将文本、图像等内容转换为高维向量(embedding),并根据这些向量之间的相似性进行搜索。例如,即使用户搜索“如何制作披萨面团”,搜索引擎也能返回与“披萨面团制作指南”相关的结果,因为它们在语义上相似。经历了倒排索引和向量索引,大约十万量级的网页会被初筛出来。
4. 多级排序
系统通常通过 B M2 5、TF-IDF、页面质量分等数千维轻特征,将十万级规模的候选页面筛选至约 1000 篇,构成初步候选集。这类系统被统称为推荐引擎。其依赖多种实体生成的海量特征,包括用户行为、页面属性、查询意图与上下文信号。例如,Google 会综合用户历史、其他用户的行为反馈、页面语义、查询含义等信息,同时还考虑上下文要素,如时间(一天中时段、一周中的具体日子)与实时新闻等外部事件。
5. 深度学习进行主排序
在初步检索阶段,Google 使用 RankBrain 和 Neural Matching 等技术来理解查询的语义,并从海量文档中筛选出初步相关的结果。RankBrain 是 Google 于 2015 年引入的机器学习系统,旨在更好地理解用户查询的含义,尤其是首次出现的查询。它通过将查询和文档转换为向量表示,计算它们之间的相似性,从而找到最相关的结果。例如,对于查询“如何制作披萨面团”,即使文档中没有完全匹配的关键词,RankBrain 也能识别出与“披萨基础”或“面团制作”相关的内容。
Neural Matching 是 Google 于 2018 年推出的另一项技术,旨在更深入地理解查询和文档之间的语义关系。它使用神经网络模型来捕捉词语之间的模糊关系,帮助 Google 更好地匹配查询和网页内容。例如,对于查询“为什么我的笔记本电脑风扇声音很大”,Neural Matching 能够理解用户可能在寻找有关过热、灰尘积聚或高 CPU 使用率的故障排除信息,即使这些词语没有直接出现在查询中。
6. 深度重排:BERT 模型的应用
在初步筛选出相关文档后,Google 使用 BERT(Bidirectional Encoder Representations from Transformers)模型对这些文档进行更精细的排序,以确保最相关的结果排在前面。BERT 是一种基于 Transformer 的预训练语言模型,能够理解词语在句子中的上下文关系。在搜索中,BERT 被用于重新排序初步检索到的文档。它通过对查询和文档进行联合编码,计算它们之间的相关性得分,从而对文档进行重新排序。例如,对于查询“停车在没有路缘的坡道上”,BERT 能够理解“没有路缘”的含义,并返回建议驾驶员将车轮朝向路边的页面,而不是误解为有路缘的情况。而对于 SEO 工程师来说,就是需要精确的学习 Google 排序和机器学习的推荐算法,来针对性的优化网页内容重而获得更高的排名展示。
以上就是典型的 Google 搜索引擎的工作流程。但是在当前的 AI 和大数据爆发的时代,用户对浏览器的交互产生了新的需求。
为什么 AI 会重塑浏览器
首先我们需要明确,为什么浏览器这一形态仍然会存在?是否存在一种第三形态,除了人工智能代理和浏览器之外的选择?
我们认为,存在即无法替代。为什么人工智能能够使用浏览器,却无法完全取代浏览器?因为浏览器是通用平台,不仅仅是读取数据的入口,更是输入数据的通用入口。这个世界不可能只有信息输入,还必须产生数据并与网站进行交互,所以整合个性化用户信息的浏览器仍将广泛存在。
我们抓住这个点:浏览器作为通用入口,不仅用于读取数据,用户往往还需要与数据进行交互。浏览器本身是存储用户指纹的绝佳场所。更复杂的用户行为和自动化行为,必须以浏览器为载体。浏览器可以存储用户的所有行为指纹、通行证等隐私信息,在自动化过程中实现无需信任的调用。而与数据交互的动作,可以演变为:
用户 → 调用 AI Agent → 浏览器。
也就是说,唯一可能被取代的部分,是符合世界演变趋势的方向——更智能化、更个性化、以及更自动化。诚然,这部分可以交给 AI Agent 来处理,但 AI Agent 本身绝非适合承载用户个性化内容的场所,因为其在数据安全与便捷性方面面临多重挑战。具体而言:
浏览器是个性化内容的存储场所:
1. 多数大型模型托管在云端,会话上下文依赖服务器保存,难以直接调用本机密码、钱包、Cookie 等敏感数据。
2. 将全部浏览和支付数据送往第三方模型,需重新获得用户授权;欧盟《DMA》与美国州级隐私法均要求数据最小化出境。
3. 自动填写双重验证验证码、调用摄像头或利用 GPU 进行 WebGPU 推理,都必须在浏览器沙盒内完成。
4. 数据上下文高度依赖浏览器,包括标签页、Cookie、IndexedDB、Service Worker Cache、Passkey 凭据以及扩展数据,都沉淀在浏览器中。
交互形式的深刻变革
回到刚开始的话题,我们使用浏览器的行为大致可以分为三种形式:读取数据、输入数据、交互数据。人工智能大模型(LLM)已经深刻改变了我们读取数据的效率和方式,过去用户基于关键词搜索网页的行为显得非常老旧且低效。
针对用户搜索行为的演化——是获取总结答案,还是点击网页,已经有不少研究进行分析。
在用户的行为模式方面, 2024 年的研究显示,在美国每 1, 000 次 Google 查询中,只有 374 次最终点击开放网页。换言之,近 63% 属于“零点击”行为。用户习惯直接从搜索结果页获取天气、汇率、知识卡片等信息。
在用户的心理方面,一项 2023 年的调查指出, 44% 受访者认为常规自然结果比精选摘要(featured snippet)更值得信赖。学术研究也发现,在存在争议或无统一真相的议题中,用户更偏好包含多来源链接的结果页。
也就是说,确实有一部分用户对 AI 摘要的信赖度不高,但也有相当比例的用户行为已经转向“零点击”。所以,AI 浏览器仍然需要探索一个恰当的交互形态——特别是在数据读取这一部分,因为当前大模型的“幻觉问题”(hallucination)仍未根除,许多用户仍难以完全信任自动生成的内容摘要。在这方面,如果将大模型嵌入浏览器,实际上不需要对浏览器进行颠覆性变革,只需逐步解决模型的准确性与可控性,这项改进也正在持续推进中。
而真正可能触发浏览器大规模变革的,是数据交互这一层。过去人们通过输入关键字完成交互——这是浏览器能理解的极限。而现在,用户越来越倾向于使用一整段自然语言描述复杂任务,比如:
● “寻找纽约到洛杉矶某个时间段的直飞机票”
● “寻找纽约飞上海然后到洛杉矶的机票”
这些行为,即使对人类来说也需要耗费大量时间去访问多个网站、收集与比较数据。但这些 Agentic Tasks(代理任务)正在逐步被 AI Agent 接管。
这也符合历史演进的方向:自动化与智能化。人们渴望解放双手,AI Agent 必将深度嵌入浏览器。未来的浏览器必须为全自动化而设计,尤其要考虑:
● 如何兼顾人类阅读体验与 AI Agent 可解析性,
● 如何在同一个页面上,既服务于用户,也服务于代理模型。
只有满足这两者的设计,浏览器才能真正成为 AI Agent 执行任务的稳定载体。
接下来,我们将聚焦五个备受关注的项目,包括 Browser Use、Arc(The Browser Company)、Perplexity、Brave 以及 Donut。这些项目分别代表了 AI 浏览器的未来演进方向,及其在 Web3 和 Crypto 场景中的原生结合潜力。
Browser Use
这正是 Perplexity 和 Browser Use 获得巨额融资背后的核心逻辑所在。尤其是 Browser Use,是 2025 年上半年涌现出的第二个最具确定性与增长潜力的创新机会。

Browser Use, source: Browser Use
Browser 是构建了一个真正意义上的语义层,其核心在于为下一代浏览器构建了语义识别架构。
Browser Use 把传统「DOM=给人看的节点树」重新解码成「语义 DOM=给 LLM 看的指令树」,让代理无需“看片点坐标”就能精准点击、填写与上传;这条路线以“结构化文本 → 函数调用”取代视觉 OCR 或坐标 Selenium,所以执行更快、token 更省、出错更少。TechCrunch 称之为“让 AI 真正读懂网页的胶水层”,而 3 月完成的 1700 万美元种子轮正是押注这一底层革新。
HTML 渲染后形成标准 DOM 树;浏览器再派生一棵 accessibility tree,为屏幕阅读器提供更丰富的“角色”与“状态”标签。
1. 把每个可交互元素(<button>,<input> 等)抽象成 JSON 片段,附带 角色、可见性、坐标、可执行动作 等元数据;
2. 将整棵页面转译成扁平化「语义节点清单」,供 LLM 在系统提示里一次性读取;
3. 接收 LLM 输出的高层指令(如 click(node_)),回放到真浏览器。官方博客把这个过程称作“把网站接口变成 LLM 可解析的 structured text”
同时,一旦这套标准被引入 W 3 C,那么可以很大程度上解决浏览器输入的问题。我们以 The Browser Company 的公开信和案例,来进一步阐述为什么 The Browser Company 的想法是错误的。
Arc
The Browser Company (Arc 母公司) 在其公开信中表示,ARC 浏览器将进入常规维护阶段,团队将重心会放在完全面向 AI 的浏览器 DIA。信中也坦言,目前尚未确定 DIA 的具体实现路径。同时,团队在信中提出了若干对未来浏览器市场的预测。基于这些预测,我们进一步认为,若要真正颠覆现有浏览器格局,关键在于对交互侧的输出做出改变。
以下是我们截取的三个来自 ARC 团队对未来浏览器市场的预测。
Webpages won’t be the primary interface anymore. Traditional browsers were built to load webpages. But increasingly, webpages — apps, articles, and files — will become tool calls with AI chat interfaces. In many ways, chat interfaces are already acting like browsers: they search, read, generate, respond. They interact with APIs, LLMs, databases. And people are spending hours a day in them. If you’re skeptical, call a cousin in high school or college — natural language interfaces, which abstract away the tedium of old computing paradigms, are here to stay.
But the Web isn’t going anywhere — at least not anytime soon. Figma and The New York Times aren’t becoming less important. Your boss isn’t ditching your team’s SaaS tools. Quite the opposite. We’ll still need to edit documents, watch videos, read weekend articles from our favorite publishers. Said more directly: webpages won’t be replaced — they’ll remain essential. Our tabs aren’t expendable, they are our core context. That is why we think the most powerful interface to AI on desktop won’t be a web browser or an AI chat interface — it’ll be both. Like peanut butter and jelly. Just as the iPhone combined old categories into something radically new, so too will AI browsers. Even if it’s not ours that wins.
New interfaces start from familiar ones. In this new world, two opposing forces are simultaneously true. How we all use computers is changing much faster (due to AI) than most people acknowledge. Yet at the same time, we’re much farther from completely abandoning our old ways than AI insiders give credit for. Cursor proved this thesis in the coding space: the breakthrough AI app of the past year was an (old) IDE — designed to be AI-native. OpenAI confirmed this theory when they bought Windsurf (another AI IDE), despite having Codex working quietly in the background. We believe AI browsers are next.
首先,其认为 Webpages 不再成为主要的交互界面。不可否认,这是一个具有挑战性的判断,也正是我们对其创始人反思结果持保留态度的关键所在。在我们看来,该观点显著低估了浏览器的作用,也正是其在探索 AI 浏览器路径时忽视的关键问题。
大模型在意图捕捉方面表现优异,例如理解“帮我订机票”这样的指令。然而,在信息密度承载能力上,它们仍显不足。当用户需要一个如仪表盘、彭博终端风格的记事本,或类似 Figma 的可视化画布时,没有什么能比像素级精度排列的专用网页更具优势。每款产品都量身定制的人体工程学设计——图表、拖放功能、热键——并非装饰性的浮渣,而是压缩认知的可供性。这些能力是简单对话式交互无法承载的。以 Gate.com 为例,若用户希望进行投资操作,仅依赖 AI 对话远远不够,因为用户对信息输入、精度与结构化呈现有着高度依赖。
RC 团队在其路径设想中存在一个本质性偏差,即未能清晰地区分“交互”由输入与输出两个维度构成。在输入侧,其观点在某些场景下具有一定合理性,AI 的确可以提升指令式交互的效率;但在输出侧,该判断明显失衡,忽略了浏览器在信息呈现与个性化体验中的核心作用。例如,Reddit 拥有其独特的布局方式和信息架构,而 AAVE 则有着完全不同的界面与结构。浏览器作为一个既容纳高度私密性数据,又能通用渲染多样化产品界面的平台,浏览器在输入层的替代性本就有限,而在输出侧,其复杂性与不可标准化特性更使其难以被颠覆。相较之下,当前市面上的 AI 浏览器更多集中在“输出总结”层面:摘要网页、提炼信息、生成结论,尚不足以构成对 Google 等主流浏览器或搜索体系的根本性挑战,分瓜的也只是搜索总结的市场份额。
因此,真正能够撼动市占率高达 66% 的 Chrome 的,注定不会是“下一个 Chrome”。要实现这一颠覆,必须对浏览器的渲染模式进行根本性重塑,使其能够适配智能时代 AI Agent 主导下的交互需求,尤其是在输入侧的架构设计上。正因如此,我们更认可 Browser Use 所采取的技术路径——其关注点在于浏览器底层机制的结构性变革。任何系统一旦实现“原子化”或“模块化”,其由此衍生出的可编程性与组合性将带来极具破坏力的颠覆潜力,而这正是 Browser Use 当前所推进的方向。
总结而言,AI Agent 的运行仍高度依赖浏览器的存在。浏览器不仅是复杂个性化数据的主要存储场所,也是多样化应用的通用渲染界面,因此将在未来继续作为核心交互入口。随着 AI Agent 深度嵌入浏览器以完成固定任务,其将通过调用用户数据与特定应用进行交互,即主要作用于输入侧。为此,浏览器的现有渲染模式需进行创新,以实现对 AI Agent 的最大程度兼容与适配,从而更有效地捕捉应用。
Perplexity
Perplexity 是一个以其推荐系统著称的 AI 搜索引擎,最新估值高达 140 亿美元,较 2024 年 6 月的 30 亿美元增长近 5 倍。月均处理搜索查询量超过 4 亿次, 2024 年 9 月处理了约 2.5 亿次查询,用户查询量同比增长 8 倍,月活跃用户超过 3000 万。
其主要的特点是能够实时的总结页面,在获取即时信息方面占据优势。今年初,其开始构建自己的原生浏览器 Comet。Perplexity 把即将发布的 Comet 描述成一个不仅“显示”网页、更能“思考”网页的浏览器。官方称它将在浏览器内部深度嵌入 Perplexity 的答案引擎,这是乔布斯式的“整机”思路:将 AI 任务深埋到浏览器底层,而非做侧边栏插件。用带引用的简洁答案取代传统的“十条蓝色链接”,直接与 Chrome 竞争。

Google I/O 2025
但其仍需解决两个核心问题:高搜索成本以及来自边际用户的低利润率。尽管 Perplexity 在 AI 搜索领域已处于领先位置,但 Google 在 2025 年 I/O 大会上同样宣布对其核心产品进行大规模智能化重塑。针对浏览器的重塑,Google 推出了一个新的浏览器标签页体验,名为 AI Model,集成了 Overview、Deep Research 以及未来的 Agentic 功能,整体项目被称为 “Project Mariner”。
Google 正在积极的进行 AI 重塑,因此仅凭表层的功能模仿,例如 Overview、DeepResearch 或 Agentics,难以真正对其构成威胁。真正有可能在混沌中建立新秩序的,将是从底层重构浏览器架构、将大语言模型(LLM)深度嵌入浏览器内核,在交互方式上实现根本性的变革。
Brave
Brave 是 Crypto 行业里面最早期也是最成功的浏览器,其基于 Chromium 架构,因此能够兼容 Google Store 上的插件。其依靠隐私和浏览赚取 Tokens 这一模式来吸引用户。Brave 的发展路径在一定程度上展现了其成长潜力。但是从产品角度来看,隐私固然重要,但其需求仍主要集中于特定用户群体,对大众而言隐私意识尚未成为主流决策因素。因此,试图依靠该特性颠覆现有巨头的可能性较低。
截至目前,Brave 的月活跃用户已达到 8, 270 万,日活跃用户为 3, 560 万,市场份额约为 1% – 1.5% 。用户规模呈持续增长态势:从 2019 年 7 月的 600 万,增长至 2021 年 1 月的 2, 500 万, 2023 年 1 月达 5, 700 万,至 2025 年 2 月突破 8, 200 万,年均复合增长率仍维持在两位数水平。其月均搜索查询量约为 13.4 亿次,约为 Google 的 0.3% 。
以下是 Brave 的迭代路线图。
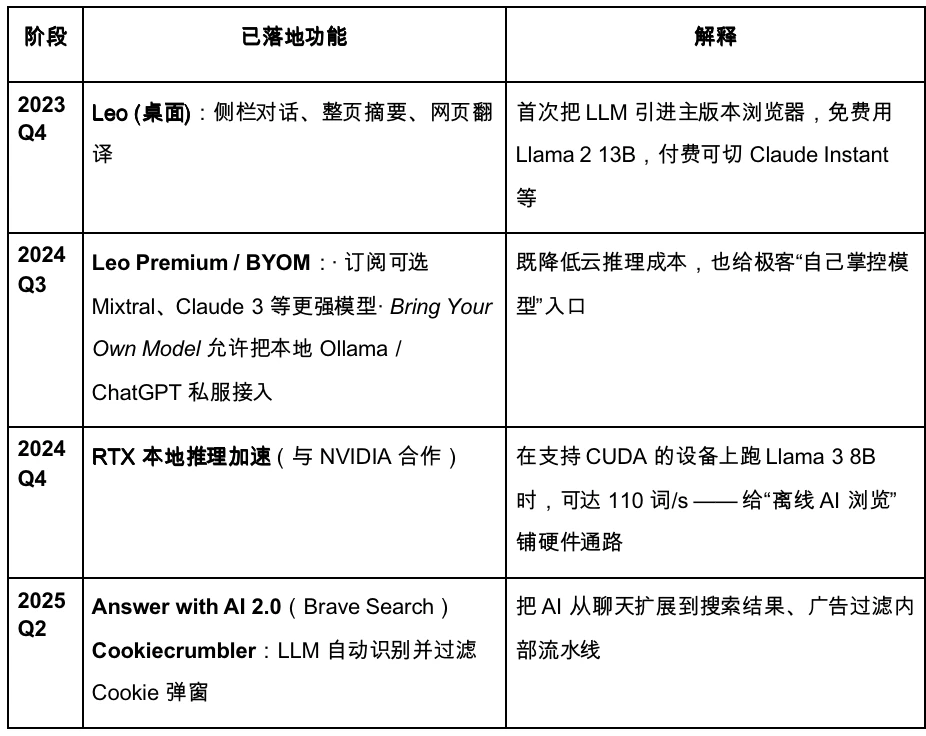
Brave 正计划升级为隐私优先的 AI 浏览器。然而,受限于其获取用户数据较少,导致大模型的可定制化程度较低,反而不利于实现快速且精准的产品迭代。在即将到来的 Agentic Browser 时代,Brave 或将在特定注重隐私的用户群体中保有稳定份额,但难以成为主要玩家。其 AI 助手 Leo 更类似于外挂插件,仅在现有产品基础上进行功能性增强,具备一定的内容总结能力,但尚无全面转向 AI Agent 的明确战略,交互层面的革新仍显不足。
Donut
近期,Crypto 行业在 Agentic Browser 领域亦有所进展。初创项目 Donut 于 Pre-seed 轮获得了 700 万美元融资,由红杉中国(Hongshan)、HackVC 与 Bitkraft Ventures 共同领投。目前项目仍处于早期构想阶段,愿景在于实现“探索—决策—加密原生执行”(Discovery, Decision-making, and Crypto-native Execution)的一体化能力。
这一方向的核心在于结合加密原生的自动化执行路径。正如 a16z 所预言,未来 Agent 有望取代搜索引擎成为主要流量入口,创业者将不再围绕 Google 排序算法展开竞争,而是争夺由 Agent 执行所带来的访问和转化流量。业界已将这一趋势称为“AEO”(Answer / Agent Engine Optimization),或更进一步的“ATF”(Agentic Task Fulfilment),即不再优化搜索排名,而是直接服务于能够替用户完成下单、订票、写信等任务的智能模型。
给创业者
首先,必须承认:Browser 本身依旧是互联网世界最大的未被重构的“总入口”。全球桌面用户约 21 亿、移动端超 43 亿,它是数据输入、交互行为、个性化指纹存储的共同载体。这个形态之所以存续,不是因为惯性,而是因为浏览器天然具备双向属性:既是数据“读入口”,也是行为“写出口”。
因此,对于创业者而言,真正具备颠覆潜力的并非“页面输出”层面的优化。即便能在新标签页中实现类似 Google 的 AI 概览功能,本质上仍属于浏览器插件层的迭代,尚未构成范式的根本性变革。真正的突破口在于“输入侧”——即如何使 AI Agent 主动调用创业者的产品,以完成具体任务。这将成为未来产品能否嵌入 Agent 生态、获得流量与价值分配的关键。
搜索时代拼“点击”;代理时代拼“调用”。
如果你是一名创业者,不妨把你的产品重新想象成一颗 API 组件——让智能体不仅能“读懂”它,更能“调用”它。这就要求你在产品设计一开始就考虑三个维度:
一、接口结构标准化:你的产品是“可调用”的么?
产品是否具备被智能体调用的能力,取决于其信息结构能否标准化并抽象为明确的 schema。例如,用户注册、下单按钮、评论提交等关键操作,是否可通过语义化的 DOM 结构或 JSON 映射进行描述?系统是否提供状态机,使 Agent 能够稳定复现用户行为流程?用户在页面上的交互是否支持脚本化还原?是否具备稳定访问的 WebHook 或 API Endpoint?
这正是 Browser Use 融资成功的本质原因——它将浏览器从平铺渲染的 HTML 转变为一棵可被 LLM 调用的语义树。对于创业者而言,在网页产品中引入类似的设计理念,即是在为 AI Agent 时代进行结构化适配。
二、身份与通行:你能帮 Agent“越过信任障壁”吗?
AI 代理要完成交易、调用支付或资产,需要某种可信中间层——你能成为它吗?浏览器天然可以读取本地存储、调用钱包、识别验证码、接入双因子验证,这正是它比云端大模型更适合做执行的原因。在 Web3 场景中尤其如此:调用链上资产的接口标准并不统一,Agent 若无“身份”或“签名能力”,将寸步难行。
所以,对 Crypto 创业者而言,这里有一个极具想象力的空白区:“区块链世界的 MCP(Multi Capability Platform)”。这既可以是一个通用指令层(让 Agent 调用 Dapp),也可以是标准化的合约接口集,甚至是某种运行在本地的轻量钱包+身份中台。
三、流量机制的再理解:未来不是 SEO,是 AEO / ATF
过去你要争取 Google 的算法青睐;现在你要被 AI Agent 嵌入进任务链里。这意味着产品要有清晰任务颗粒度:不是一个“页面”,而是一串“可调用能力单元”;意味着你要开始做 Agent 优化(AEO)或任务调度适配(ATF):例如注册流程是否可简化为结构化步骤、定价是否可通过接口拉取、库存是否实时可查;
你甚至要开始适配不同 LLM 框架下的调用语法——OpenAI 和 Claude 对函数调用、tool usage 的偏好并不一致。Chrome 是通往旧世界的终端,而不是通往新世界的入口。真正有未来的创业项目,不是再造一个浏览器,而是让现有浏览器为 Agent 服务,为新一代的“指令流”建立桥梁。
你要构建的,是 Agent 调用你的世界的“接口语法”;
你要争取的,是成为智能体信任链中的一个环节;
你要搭建的,是下一个搜索模式里的“API 城堡”。
如果说 Web2 是靠 UI 抓住用户的注意力,那 Web3 + AI Agent 时代,就是靠调用链抓住 Agent 的执行意图。
免责声明:
本内容不构成任何要约、招揽、或建议。您在做出任何投资决定之前应始终寻求独立的专业建议。请注意, Gate 及/或 Gate Ventures 可能会限制或禁止来自受限制地区的所有或部分服务。请阅读其适用的用户协议了解更多信息。
关于 Gate Ventures
Gate Ventures 是 Gate 旗下的风险投资部门,专注于对去中心化基础设施、生态系统和应用程序的投资,这些技术将在 Web 3.0 时代重塑世界。Gate Ventures 与全球行业领袖合作,赋能那些拥有创新思维和能力的团队和初创公司,重新定义社会和金融的交互模式。
官网:https://ventures.gate.io/
Twitter:https://x.com/gate_ventures
Medium:https://medium.com/gate_ventures


