


原文标题:《Binius: highly efficient proofs over binary fields》
撰文:Vitalik
编译:Kate,火星财经
来源:火星财经
这篇文章主要针对大致熟悉 2019 年时代密码学的读者,特别是 SNARK 和 STARK。如果你不是,我建议你先阅读这些文章。特别感谢 Justin Drake, Jim Posen, Benjamin Diamond 和 Radi Cojbasic 的反馈和评论。
在过去的两年中,STARK 已经成为一种关键且不可替代的技术,可以有效地对非常复杂的语句进行易于验证的加密证明(例如,证明以太坊区块是有效的)。其中一个关键原因是字段大小小:基于椭圆曲线的 SNARK 要求您在 256 位整数上工作才能足够安全,而 STARK 允许您使用更小的字段大小,效率更高:首先是 Goldilocks 字段(64 位整数),然后是 Mersenne31 和 BabyBear(均为 31 位)。由于这些效率的提高,使用 Goldilocks 的 Plonky2 在证明多种计算方面比其前辈快数百倍。
一个自然而然的问题是:我们能否将这一趋势引向合乎逻辑的结论,通过直接在零和一上操作来构建运行速度更快的证明系统?这正是 Binius 试图做的事情,使用了许多数学技巧,使其与三年前的 SNARK 和 STARK 截然不同。这篇文章介绍了为什么小字段使证明生成更有效率,为什么二进制字段具有独特的强大功能,以及 Binius 用来使二进制字段上的证明如此有效的技巧。
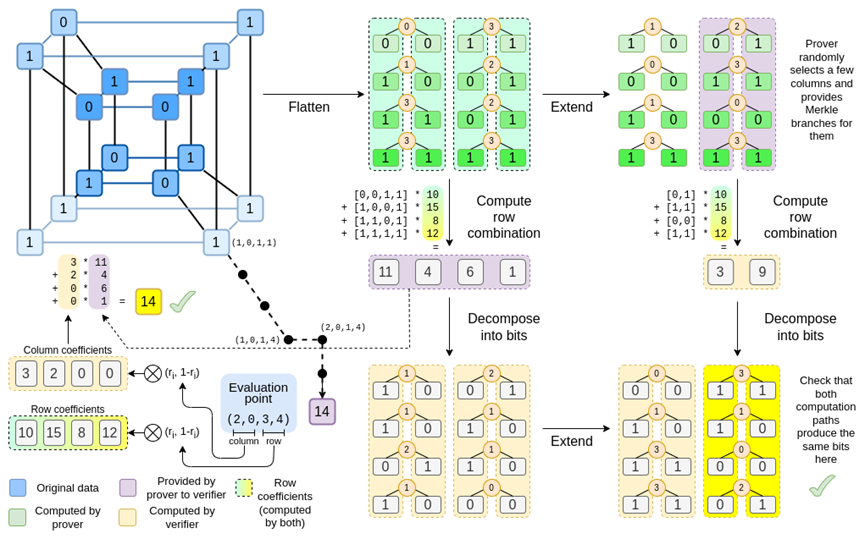
Binius。在这篇文章的最后,你应该能够理解此图的每个部分。
回顾:有限域(finite fields)
加密证明系统的关键任务之一是对大量数据进行操作,同时保持数字较小。如果你可以将一个关于大型程序的语句压缩成一个包含几个数字的数学方程,但是这些数字与原始程序一样大,那么你将一无所获。
为了在保持数字较小的情况下进行复杂的算术,密码学家通常使用模运算 (modular arithmetic)。我们选择一个质数「模数」p。% 运算符的意思是「取余数」:15%7=1,53=3,等等。(请注意,答案总是非负数的,所以例如 -1=9)
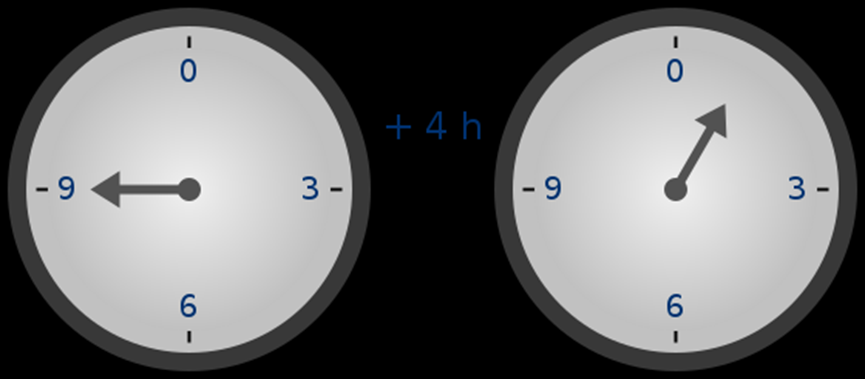
你可能已经在时间的加减上下文中见过模运算 ( 例如,9 点过 4 小时是几点?但在这里,我们不只是对某个数进行加、减模,我们还可以进行乘、除和取指数。
我们重新定义:
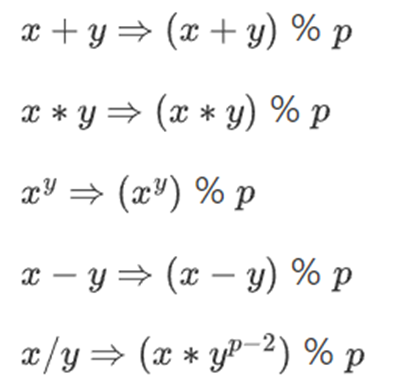
以上规则都是自洽的。例如,如果 p=7,那么:
5+3=1(因为 8%7=1)
1-3=5(因为 -2%7=5)
2*5=3
3/5=2
这种结构的更通用术语是有限域。有限域是一种数学结构,它遵循通常的算术法则,但其中可能的值数量有限,因此每个值都可以用固定的大小表示。
模运算 ( 或质数域 ) 是有限域最常见的类型,但也有另一种类型:扩展域。你可能已经见过一个扩展字段:复数。我们「想象」一个新元素,并给它贴上标签 i,并用它进行数学运算:(3i+2)*(2i+4)=6i*i+12i+4i+8=16i+2。我们可以同样地取质数域的扩展。当我们开始处理较小的字段时,质数字段的扩展对于保护安全性变得越来越重要,而二进制字段 (Binius 使用 ) 完全依赖于扩展以具有实际效用。
回顾:算术化
SNARK 和 STARK 证明计算机程序的方法是通过算术:你把一个关于你想证明的程序的陈述,转换成一个包含多项式的数学方程。方程的有效解对应于程序的有效执行。
举个简单的例子,假设我计算了第 100 个斐波那契数,我想向你证明它是什么。我创建了一个编码斐波那契数列的多项式 F:所以 F(0)=F(1)=1、F(2)=2、F(3)=3、F(4)=5 依此类推,共 100 步。我需要证明的条件是 F(x+2)=F(x)+F(x+1) 在整个范围内 x={0,1…98}。我可以通过给你商数来说服你:
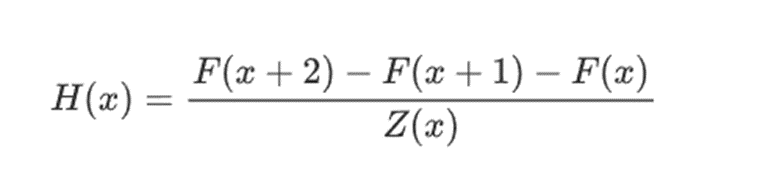
其中 Z(x) = (x-0) * (x-1) * …(x-98)。.如果我能提供有 F 且 H 满足此等式,则 F 必须在该范围内满足 F(x+2)-F(x+1)-F(x)。如果我另外验证满足 F,F(0)=F(1)=1,那么 F(100) 实际上必须是第 100 个斐波那契数。
如果你想证明一些更复杂的东西,那么你用一个更复杂的方程替换「简单」关系 F(x+2) = F(x) + F(x+1),它基本上是说「F(x+1) 是初始化一个虚拟机的输出,状态是 F(x)」,并运行一个计算步骤。你也可以用一个更大的数字代替数字 100,例如,100000000,以容纳更多的步骤。
所有 SNARK 和 STARK 都基于这种想法,即使用多项式 ( 有时是向量和矩阵 ) 上的简单方程来表示单个值之间的大量关系。并非所有的算法都像上面那样检查相邻计算步骤之间的等价性:例如,PLONK 没有,R1CS 也没有。但是许多最有效的检查都是这样做的,因为多次执行相同的检查 ( 或相同的少数检查 ) 可以更轻松地将开销降至最低。
Plonky2:从 256 位 SNARK 和 STARK 到 64 位......只有 STARK
五年前,对不同类型的零知识证明的合理总结如下。有两种类型的证明:( 基于椭圆曲线的 )SNARK 和 ( 基于哈希的 )STARK。从技术上讲,STARK 是 SNARK 的一种,但在实践中,通常使用「SNARK」来指代基于椭圆曲线的变体,而使用「STARK」来指代基于哈希的结构。SNARK 很小,因此你可以非常快速地验证它们并轻松地将它们安装在链上。STARK 很大,但它们不需要可信的设置,而且它们是抗量子的。
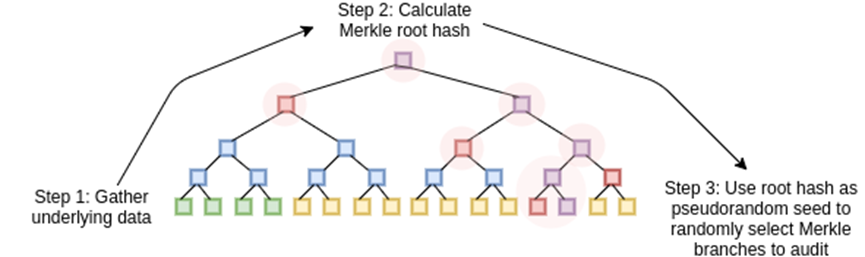
STARK 的工作原理是将数据视为多项式,计算该多项式的计算,并使用扩展数据的默克尔根作为「多项式承诺」。
这里的一个关键历史是,基于椭圆曲线的 SNARK 首先得到了广泛的使用:直到 2018 年左右,STARK 才变得足够高效,这要归功于 FRI,而那时 Zcash 已经运行了一年多。基于椭圆曲线的 SNARK 有一个关键的限制:如果你想使用基于椭圆曲线的 SNARK,那么这些方程中的算术必须使用椭圆曲线上的点数模数来完成。这是一个很大的数字,通常接近 2 的 256 次方:例如,bn128 曲线为 21888242871839275222246405745257275088548364400416034343698204186575808495617。但实际的计算使用的是小数字:如果你用你最喜欢的语言来考虑一个「真正的」程序,它使用的大部分东西是计数器,for 循环中的索引,程序中的位置,代表 True 或 False 的单个位,以及其他几乎总是只有几位数长的东西。
即使你的「原始」数据由「小」数字组成,证明过程也需要计算商数、扩展、随机线性组合和其他数据转换,这将导致相等或更大数量的对象,这些对象的平均大小与你的字段的全部大小一样大。这造成了一个关键的低效率:为了证明对 n 个小值的计算,你必须对 n 个大得多的值进行更多的计算。起初,STARK 继承了 SNARK 使用 256 位字段的习惯,因此也遭受了同样的低效率。

一些多项式求值的 Reed-Solomon 扩展。尽管原始值很小,但额外的值都将扩展到字段的完整大小 ( 在本例中是 2 的 31 次方 -1)
2022 年,Plonky2 发布。Plonky2 的主要创新是对一个较小的质数进行算术取模:2 的 64 次方 – 2 的 32 次方 + 1 = 18446744067414584321。现在,每次加法或乘法总是可以在 CPU 上的几个指令中完成,并且将所有数据哈希在一起的速度比以前快 4 倍。但这有一个问题:这种方法只适用于 STARK。如果你尝试使用 SNARK,对于如此小的椭圆曲线,椭圆曲线将变得不安全。
为了保证安全,Plonky2 还需要引入扩展字段。检查算术方程的一个关键技术是「随机点抽样」:如果你想检查的 H(x) * Z(x) 是否等于 F(x+2)-F(x+1)-F(x),你可以随机选择一个坐标 r,提供多项式承诺开证明证明 H(r)、Z(r) 、F(r),F(r+1) 和 F(r+2),然后进行验证 H(r) * Z(r) 是否等于 F(r+2)-F(r+1)- F(r)。如果攻击者可以提前猜出坐标,那么攻击者就可以欺骗证明系统——这就是为什么证明系统必须是随机的。但这也意味着坐标必须从一个足够大的集合中采样,以使攻击者无法随机猜测。如果模数接近 2 的 256 次方,这显然是事实。但是,对于模数量是 2 的 64 次方 -2 的 32 次方 +1,我们还没到那一步,如果我们降到 2 的 31 次方 -1,情况肯定不是这样。试图伪造证明 20 亿次,直到一个人幸运,这绝对在攻击者的能力范围内。
为了阻止这种情况,我们从扩展字段中采样 r,例如,你可以定义 y,其中 y 的 3 次方=5,并采用 1、y、y 的 2 次方的组合。这将使坐标的总数增加到大约 2 的 93 次方。证明者计算的多项式的大部分不进入这个扩展域;只是用整数取模 2 的 31 次方 -1,因此,你仍然可以从使用小域中获得所有的效率。但是随机点检查和 FRI 计算确实深入到这个更大的领域,以获得所需的安全性。
从小质数到二进制数
计算机通过将较大的数字表示为 0 和 1 的序列来进行算术运算,并在这些 bit 之上构建「电路」来计算加法和乘法等运算。计算机特别针对 16 位、32 位和 64 位整数进行了优化。例如,2 的 64 次方 -2 的 32 次方 +1 和 2 的 31 次方 -1,选择它们不仅是因为它们符合这些界限,还因为它们与这些界限很吻合:可以通过执行常规的 32 位乘法来执行乘法取模 2 的 64 次方 -2 的 32 次方 +1,并在几个地方按位移位和复制输出;这个文章很好地解释了一些技巧。
然而,更好的方法是直接用二进制进行计算。如果加法可以「只是」异或,而无需担心「携带」从一个位添加 1 + 1 到下一个位的溢出?如果乘法可以以同样的方式更加并行化呢?这些优点都是基于能够用一个 bit 表示真 / 假值。
获取直接进行二进制计算的这些优点正是 Binius 试图做的。Binius 团队在 zkSummit 的演讲中展示了效率提升:
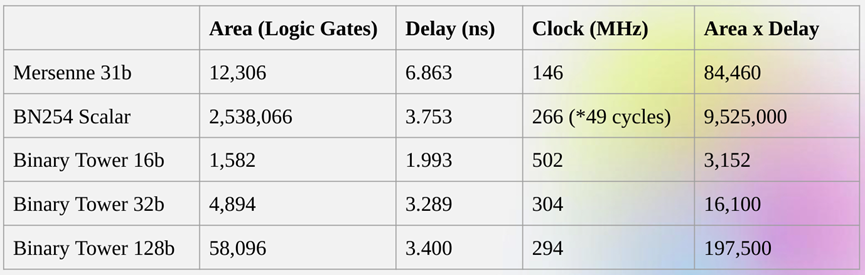
尽管「大小」大致相同,但 32 位二进制字段操作比 31 位 Mersenne 字段操作所需的计算资源少 5 倍。
从一元多项式到超立方体
假设我们相信这个推理,并且想要用 bit(0 和 1) 来做所有的事情。我们如何用一个多项式来表示十亿 bit 呢?
在这里,我们面临两个实际问题:
1.对于一个表示大量值的多项式,这些值需要在多项式的求值时可以访问:在上面的斐波那契例子中,F(0),F(1) … F(100),在一个更大的计算中,指数会达到数百万。我们使用的字段需要包含到这个大小的数字。
2.证明我们在 Merkle 树中提交的任何值 ( 就像所有 STARK 一样 ) 都需要 Reed-Solomon 对其进行编码:例如,将值从 n 扩展到 8n,使用冗余来防止恶意证明者通过在计算过程中伪造一个值来作弊。这也需要有一个足够大的字段:要将一百万个值扩展到 800 万个,你需要 800 万个不同的点来计算多项式。
Binius 的一个关键思想是分别解决这两个问题,并通过以两种不同的方式表示相同的数据来实现。首先,多项式本身。基于椭圆曲线的 SNARK、2019 时代的 STARK、Plonky2 等系统通常处理一个变量上的多项式:F(x)。另一方面,Binius 从 Spartan 协议中获得灵感,并使用多元多项式:F(x1,x2,… xk)。实际上,我们在计算的「超立方体」上表示整个计算轨迹,其中每个 xi 不是 0 就是 1。例如,如果我们想要表示一个斐波那契数列,并且我们仍然使用一个足够大的字段来表示它们,我们可以将它们的前 16 个数列想象成这样:
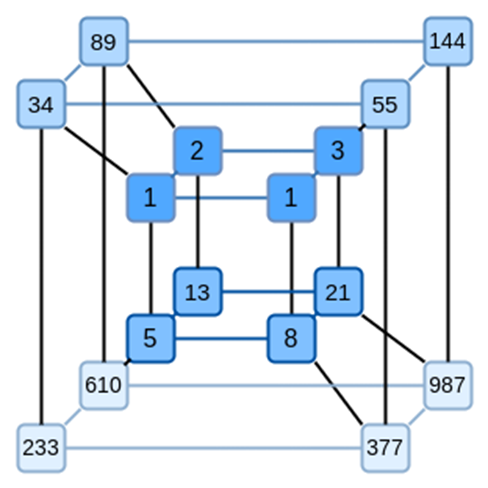
也就是说,F(0,0,0,0) 应该是 1,F(1,0,0,0) 也是 1,F(0,1,0,0) 是 2,以此类推,一直到 F(1,1,1,1)=987。给定这样一个计算的超立方体,就会有一个产生这些计算的多元线性 ( 每个变量的度数为 1) 多项式。所以我们可以把这组值看作是多项式的代表;我们不需要计算系数。
这个例子当然只是为了说明:在实践中,进入超立方体的全部意义是让我们处理单个 bit。计算斐波那契数的「Binius 原生」方法是使用一个高维的立方体,使用每组例如 16 位存储一个数字。这需要一些聪明才智来在 bit 的基础上实现整数相加,但对于 Binius 来说,这并不太难。
现在,我们来看看纠删码。STARK 的工作方式是:你取 n 值,Reed-Solomon 将它们扩展到更多的值 ( 通常 8n,通常在 2n 和 32n 之间 ),然后从扩展中随机选择一些 Merkle 分支,并对它们执行某种检查。超立方体在每个维度上的长度为 2。因此,直接扩展它是不实际的:没有足够的「空间」从 16 个值中采样 Merkle 分支。那么我们该怎么做呢?我们假设超立方体是一个正方形!
简单的 Binius - 一个例子
请参阅此处查看该协议的 python 实现。
让我们看一个示例,为了方便起见,使用正则整数作为我们的字段 ( 在实际实现中,将使用二进制字段元素 )。首先,我们将想要提交的超立方体,编码为正方形:
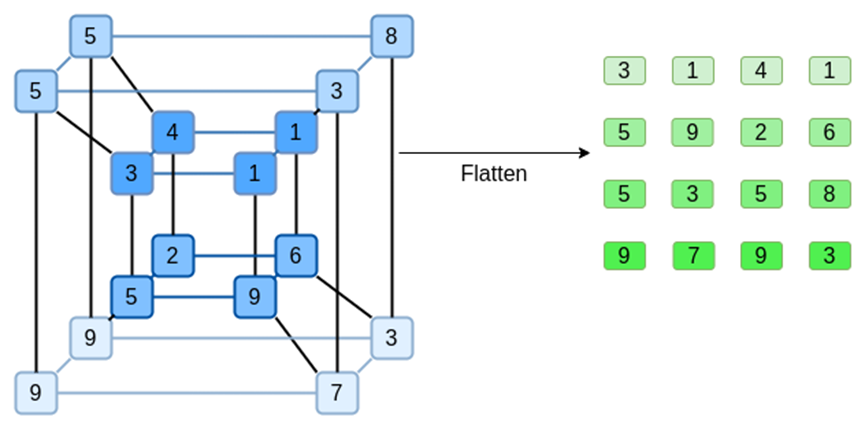
现在,我们用 Reed-Solomon 扩展正方形。也就是说,我们将每一行视为在 x ={0,1,2,3}处求值的 3 次多项式,并在 x ={4,5,6,7}处求值相同的多项式:
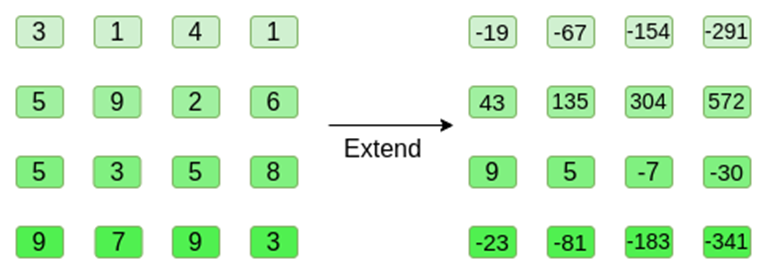
注意,数字会迅速膨胀!这就是为什么在实际实现中,我们总是使用有限域,而不是正则整数:如果我们使用整数模 11,例如,第一行的扩展将只是[3,10,0,6]。
如果你想尝试扩展并亲自验证这里的数字,可以在这里使用我的简单 Reed-Solomon 扩展代码。
接下来,我们将此扩展视为列,并创建列的 Merkle 树。默克尔树的根是我们的承诺。
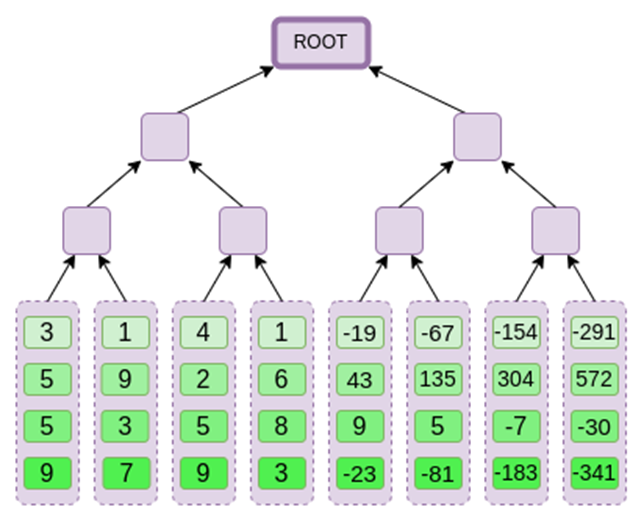
现在,让我们假设证明者想要在某个时候证明这个多项式的计算 r={r0,r1,r2,r3}。在 Binius 中有一个细微的差别,使它比其他多项式承诺方案更弱:证明者在提交到 Merkle 根之前不应该知道或能够猜测 s( 换句话说,r 应该是一个依赖于默克尔根的伪随机值 )。这使得该方案对「数据库查找」无用 ( 例如,「好吧,你给了我默克尔根,现在证明给我看 P(0,0,1,0) !」)。但是我们实际使用的零知识证明协议通常不需要「数据库查找」;他们只需要在一个随机的求值点检查多项式。因此,这个限制符合我们的目的。
假设我们选择 r={1,2,3,4} ( 此时多项式的计算结果为 -137;你可以使用此代码进行确认 )。现在,我们进入了证明的过程。我们分为 r 两部分:第一部分{1,2}表示行内列的线性组合,第二部分{3,4}表示行的线性组合。我们计算一个「张量积」,对于列部分:
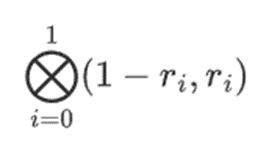
对于行部分:
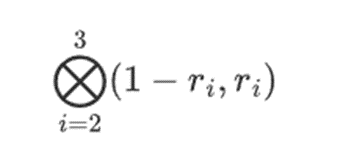
这意味着:每个集合中一个值的所有可能乘积的列表。在行情况下,我们得到:
[(1-r2)*(1-r3), (1-r3), (1-r2)*r3, r2*r3]
使用 r={1,2,3,4} ( 所以 r2=3 和 r3=4):
[(1-3)*(1-4), 3*(1-4),(1-3)*4,3*4] = [6, -9 -8 -12]
现在,我们通过采用现有行的线性组合来计算一个新的「行」t。也就是说,我们取:
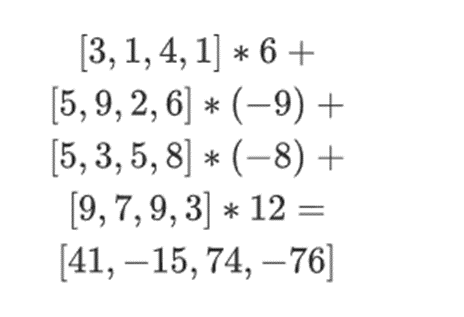
你可以把这里发生的看作是部分求值。如果我们把全张量乘积乘以所有值的全向量,你将得到计算 P(1,2,3,4) = -137。在这里,我们将仅使用一半评估坐标的偏张量乘积相乘,并将 N 值网格简化为一行根号 N 的值。如果你把此行提供给其他人,他们可以用另一半的求值坐标的张量积来完成剩下的计算。
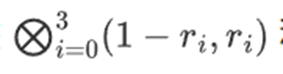
证明者向验证者提供以下新行:t 以及一些随机抽样列的 Merkle 证明。在我们的说明性示例中,我们将让证明程序只提供最后一列;在现实生活中,证明者需要提供几十列来实现足够的安全性。
现在,我们利用 Reed-Solomon 代码的线性。我们使用的关键属性是:取一个 Reed-Solomon 扩展的线性组合得到与线性组合的 Reed-Solomon 扩展相同的结果。这种「顺序独立性」通常发生在两个操作都是线性的情况下。
验证者正是这样做的。他们计算了 t,并且计算与证明者之前计算的相同的列的线性组合 ( 但只计算证明者提供的列 ),并验证这两个过程是否给出相同的答案。
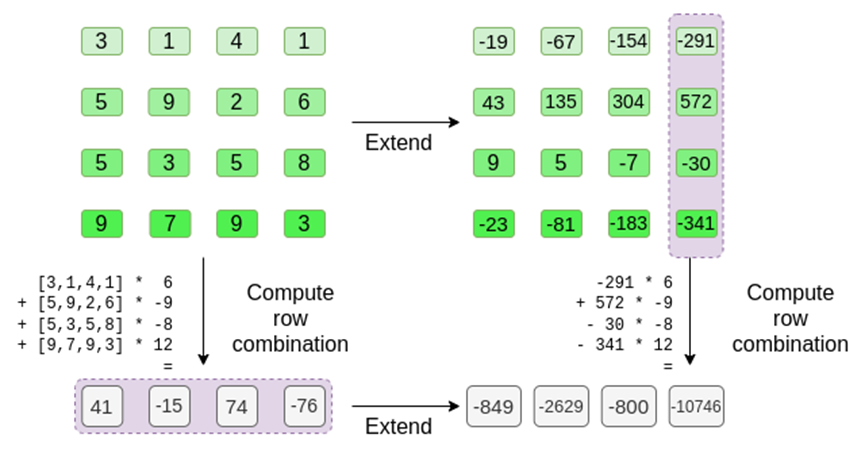
在本例中,是扩展 t,计算相同的线性组合 ([6,-9,-8,12],两者给出了相同的答案:-10746。这证明默克尔的根是「善意」构建的 ( 或者至少「足够接近」),而且它是匹配 t 的:至少绝大多数列是相互兼容的。
但是验证者还需要检查另一件事:检查多项式{r0…r3}的求值。到目前为止,验证者的所有步骤实际上都没有依赖于证明者声称的值。我们是这样检查的。我们取我们标记为计算点的「列部分」的张量积:
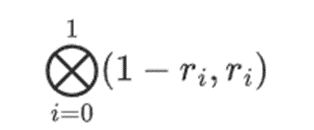
在我们的例子中,其中 r={1,2,3,4} 所以选择列的那一半是{1,2}),这等于:
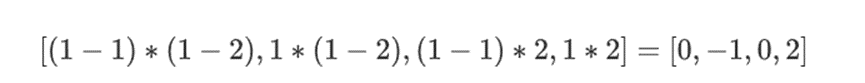
现在我们取这个线性组合 t:
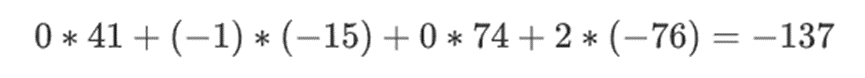
这和直接求多项式的结果是一样的。
以上内容非常接近于对「简单」Binius 协议的完整描述。这已经有了一些有趣的优点:例如,由于数据被分成行和列,因此你只需要一个大小减半的字段。但是,这并不能实现用二进制进行计算的全部好处。为此,我们需要完整的 Binius 协议。但首先,让我们更深入地了解二进制字段。
二进制字段
最小的可能域是算术模 2,它非常小,我们可以写出它的加法和乘法表:
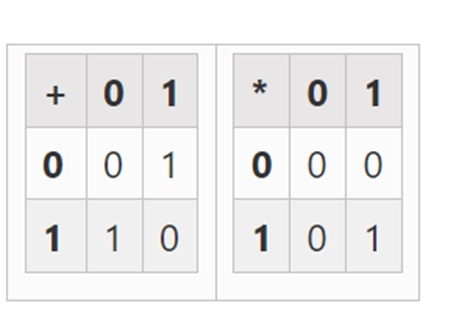
我们可以通过扩展得到更大的二进制字段:如果我们从 F2( 整数模 2) 然后定义 x 在哪里 x 的平方=x+1,我们得到以下的加法和乘法表:
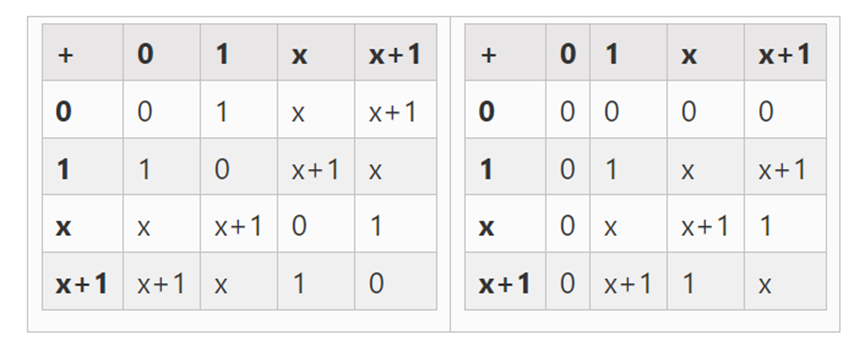
事实证明,我们可以通过重复这个构造将二进制字段扩展到任意大的大小。与实数上的复数不同,在实数上,你可以加一个新元素,但不能再添加任何元素 I (四元数确实存在,但它们在数学上很奇怪,例如:ab 不等于 ba),使用有限的字段,你可以永远添加新的扩展。具体来说,我们对元素的定义如下:
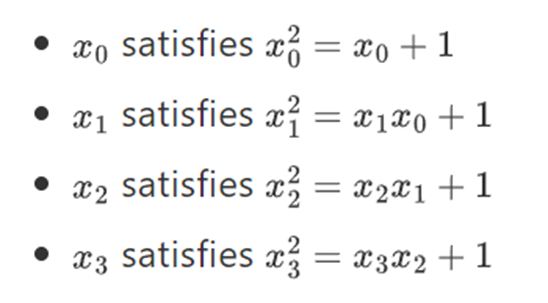
等等......。这通常被称为塔式结构,因为每一个连续的扩展都可以被看作是给塔增加了一个新的层。这并不是构造任意大小二进制字段的唯一方法,但它有一些独特的优点,Binius 利用了这些优点。
我们可以把这些数字表示成 bit 的列表。例如,1100101010001111。第一位表示 1 的倍数,第二位表示 x0 的倍数,然后后续位表示以下 x1 数的倍数: x1, x1*x0, x2, x2*x0, 依此类推。这种编码很好,因为你可以分解它:
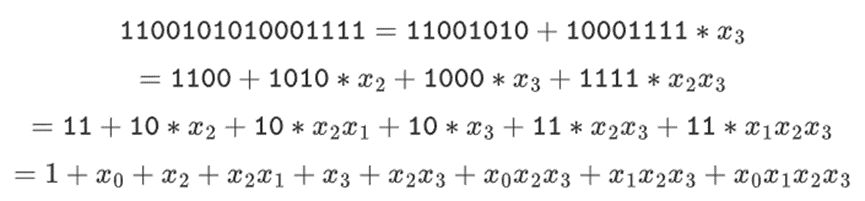
这是一种相对不常见的表示法,但我喜欢将二进制字段元素表示为整数,采用更有效 bit 在右侧的位表示。也就是说,1=1,x0=01=2,1+x0=11=3,1+x0+x2=11001000 =19, 等等。在这个表达式中,是 61779。
二进制字段中的加法只是异或 ( 顺便说一句,减法也是如此 );注意,这意味着 x+x=0 对于任何 x。将两个元素 x*y 相乘,有一个非常简单的递归算法:把每个数字分成两半:
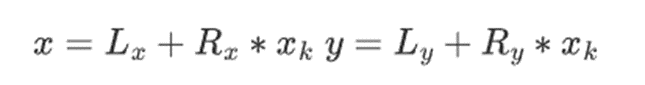
然后,将乘法拆分:
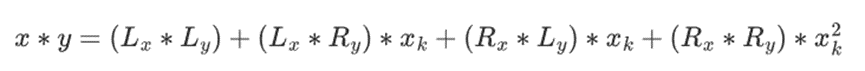
最后一部分是唯一有点棘手的,因为你必须应用简化规则。有更有效的方法来做乘法,类似于 Karatsuba 算法和快速傅里叶变换,但我将把它作为一个练习留给有兴趣的读者去弄清楚。
二进制字段中的除法是通过结合乘法和反转来完成的。「简单但缓慢」的反转方法是广义费马小定理的应用。还有一个更复杂但更有效的反演算法,你可以在这里找到。你可以使用这里的代码来玩二进制字段的加法,乘法和除法。
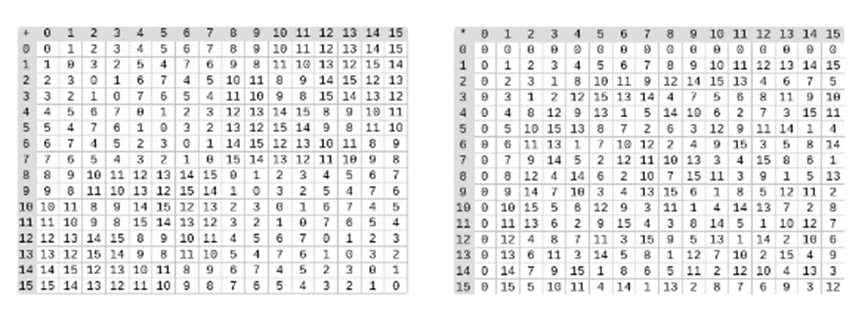
左图:四位二进制字段元素(即仅由 1、x0、x1、x0x1)的加法表。右图:四位二进制字段元素的乘法表。
这种类型的二进制字段的美妙之处在于,它结合了「正则」整数和模运算的一些最好的部分。与正则整数一样,二进制字段元素是无界的:你可以随意扩展。但就像模运算一样,如果你在一定的大小限制内对值进行运算,你所有的结果也会保持在相同的范围内。例如,如果取 42 连续幂,则得到:
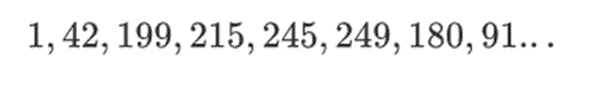
255 步之后,你就回到 42 的 255 次方=1,就像正整数和模运算一样,它们遵循通常的数学定律:a*b=b*a、a*(b+c)=a*b+a*c,甚至还有一些奇怪的新法律。
最后,二进制字段可以方便地处理 bit:如果你用适合 2 的 k 次方的数字做数学运算,那么你所有的输出也将适合 2 的 k 次方 bit。这避免了尴尬。在以太坊的 EIP-4844 中,一个 blob 的各个「块」必须是数字模 52435875175126190479447740508185965837690552500527637822603658699938581184513,因此编码二进制数据需要扔掉一些空间,并在应用层进行额外的检查,以确保每个元素存储的值小于 2 的 248 次方。这也意味着二进制字段运算在计算机上是超级快的——无论是 CPU,还是理论上最优的 FPGA 和 ASIC 设计。
这一切都意味着我们可以像上面所做的 Reed-Solomon 编码那样做,以一种完全避免整数「爆炸」的方式,就像我们在我们的例子中看到的那样,并且以一种非常「原生」的方式,计算机擅长的那种计算。二进制字段的「拆分」属性——我们是如何做到的 1100101010001111=11001010+10001111*x3,然后根据我们的需要进行拆分,这对于实现很大的灵活性也是至关重要的。
完整的 Binius
请参阅此处查看该协议的 python 实现。
现在,我们可以进入「完整的 Binius」,它将「简单的 Binius」调整为 (i) 在二进制字段上工作,(ii) 让我们提交单个 bit。这个协议很难理解,因为它在查看比特矩阵的不同方式之间来回切换;当然,我花了更长的时间来理解它,这比我通常理解加密协议所花的时间要长。但是一旦你理解了二进制字段,好消息是 Binius 所依赖的「更难的数学」就不存在了。这不是椭圆曲线配对,在椭圆曲线配对中有越来越深的代数几何兔子洞要钻;在这里,你只需要二进制字段。
让我们再看一下完整的图表:
到目前为止,你应该熟悉了大多数组件。将超立方体「扁平化」成网格的思想,将行组合和列组合计算为评价点的张量积的思想,以及检验「Reed-Solomon 扩展再计算行组合」和「计算行组合再 Reed-Solomon 扩展」之间的等价性的思想,都是在简单的 Binius 中实现的。
「完整的 Binius」有什么新内容?基本上有三件事: 超立方体和正方形中的单个值必须是 bit(0 或 1)。 扩展过程通过将 bit 分组为列并暂时假定它们是较大的字段元素,将 bit 扩展为更多的 bit 在行组合步骤之后,有一个元素方面的「分解为 bit」步骤,该步骤将扩展转换回 bit
我们将依次讨论这两种情况。首先,新的延期程序。Reed-Solomon 代码有一个基本的限制,如果你要扩展 n 到 k*n,则需要在具有 k*n 不同值的字段中工作,这些值可以用作坐标。使用 F2 (又名 bit),你无法做到这一点。因此,我们所做的是,将相邻 F2 的元素「打包」在一起形成更大的值。在这里的示例中,我们一次将两个 bit 打包到 {0,1,2,3}元素中,因为我们的扩展只有四个计算点,所以这对我们来说已经足够了。在「真实」证明中,我们可能一次返回 16 位。然后,我们对这些打包值执行 Reed-Solomon 代码,并再次将它们解压缩为 bit。
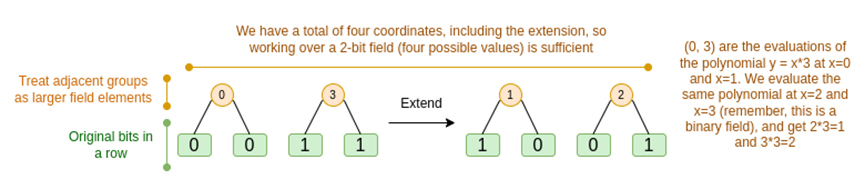
现在,行组合。为了使「在随机点求值」检查加密安全,我们需要从一个相当大的空间 ( 比超立方体本身大得多 ) 中对该点进行采样。因此,虽然超立方体内的点是位,但超立方体外的计算值将大得多。在上面的例子中,「行组合」最终是[11,4,6,1]。
这就出现了一个问题:我们知道如何将 bit 组合成一个更大的值,然后在此基础上进行 Reed-Solomon 扩展,但是如何对更大的值对做同样的事情呢?
Binius 的技巧是按 bit 处理:我们查看每个值的单个 bit ( 例如:对于我们标为「11」的东西,即[1,1,0,1] ),然后按行扩展。对象上执行扩展过程。也就是说,我们对每个元素的 1 行执行扩展过程,然后在 x0 行上,然后在「 x1」行上,然后在 x0x1 行上,依此类推(好吧,在我们的玩具示例中,我们停在那里,但在实际实现中,我们将达到 128 行(最后一个是 x6*…*x0 ))
回顾: 我们把超立方体中的 bit,转换成一个网格 然后,我们将每行上的相邻 bit 组视为更大的字段元素,并对它们进行算术运算以 Reed-Solomon 扩展行 然后,我们取每列 bit 的行组合,并获得每一行的 bit 列作为输出 ( 对于大于 4x4 的正方形,要小得多 ) 然后,我们把输出看成一个矩阵,再把它的 bit 当作行
为什么会这样呢?在「普通」数学中,如果你开始将一个数字按 bit 切片,( 通常 ) 以任意顺序进行线性运算并得到相同结果的能力就会失效。例如,如果我从数字 345 开始,我把它乘以 8,然后乘以 3,我得到 8280,如果把这两个运算反过来,我也得到 8280。但如果我在两个步骤之间插入一个「按 bit 分割」操作,它就会崩溃:如果你做 8 倍,然后做 3 倍,你会得到:
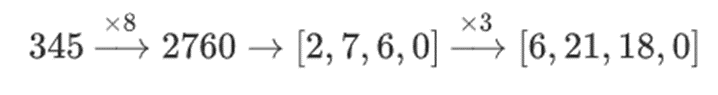
但是,如果你做 3 倍,然后做 8 倍,你会得到:
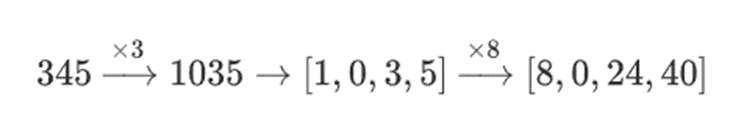
但在用塔结构构建的二进制场中,这种方法确实有效。原因在于它们的可分离性:如果你用一个大的值乘以一个小的值,在每个线段上发生的事情,会留在每个线段上。如果我们 1100101010001111 乘以 11,这和第一次分解 1100101010001111 是一样的,为
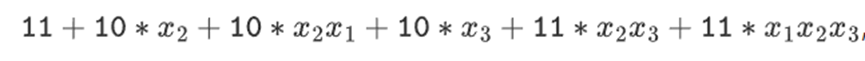
然后将每个分量分别乘以 11 相同。
把它们放在一起
一般来说,零知识证明系统的工作原理是对多项式进行陈述,同时表示对底层评估的陈述:就像我们在斐波那契的例子中看到的那样,F(X+2)-F(X+1)-F(X) = Z(X)*H(X) 同时检查斐波那契计算的所有步骤。我们通过在随机点证明求值来检查关于多项式的陈述。这种随机点的检查代表整个多项式的检查:如果多项式方程不匹配,则它在特定随机坐标处匹配的可能性很小。
在实践中,效率低下的一个主要原因是在实际程序中,我们处理的大多数数字都很小:for 循环中的索引、True/False 值、计数器和类似的东西。但是,当我们使用 Reed-Solomon 编码「扩展」数据以使基于 Merkle 证明的检查安全所需的冗余时,大多数「额外」值最终会占用字段的整个大小,即使原始值很小。
为了解决这个问题,我们想让这个场越小越好。Plonky2 将我们从 256 位数字降至 64 位数字,然后 Plonky3 进一步降至 31 位。但即使这样也不是最优的。使用二进制字段,我们可以处理单个 bit。这使得编码「密集」:如果你的实际底层数据有 n 位,那么你的编码将有 n 位,扩展将有 8 * n 位,没有额外的开销。
现在,让我们第三次看这个图表:
在 Binius 中,我们致力于一个多线性多项式:一个超立方体 P(x0,x1,…xk),其中单个评估 P(0,0,0,0),P(0,0,0,1) 直到 P(1,1,1,1), 保存我们关心的数据。为了证明某一点上的计算,我们将相同的数据「重新解释」为一个平方。然后,我们扩展每一行,使用 Reed-Solomon 编码,为随机默克尔分支查询提供安全所需的数据冗余。然后我们计算行的随机线性组合,设计系数,使新的组合行实际上包含我们关心的计算值。这个新创建的行 ( 被重新解释为 128 行 bit) 和一些随机选择的带有 Merkle 分支的列都被传递给验证者。
然后,验证器执行「扩展的行组合」( 或者更确切地说,是扩展的几列 ) 和「行组合的扩展」,并验证两者是否匹配。然后计算一个列组合,并检查它是否返回证明者所声明的值。这就是我们的证明系统 ( 或者更确切地说,多项式承诺方案,它是证明系统的关键组成部分 )。
我们还没有讲到什么? 有效的算法来扩展行,这是实际提高验证器计算效率所必需的。我们在二进制字段上使用快速傅里叶变换,在这里描述 ( 尽管确切的实现将有所不同,因为这篇文章使用了一个不基于递归扩展的效率较低的结构 )。 算术化。一元多项式很方便,因为您可以做一些事情,例如 F(X+2)-F(X+1)-F(X) = Z(X)*H(X) 将计算中相邻的步骤联系起来。在超立方体中,「下一步」的解释远不如「X+1」。你可以做 X+k,k 的幂,但是这种跳跃行为会牺牲 Binius 的许多关键优势。Binius 论文介绍了解决方案。参见第 4.3 节 ),但这本身就是一个「深兔子洞」。 如何安全地进行特定值检查。斐波那契例子需要检查关键边界条件:F(0)=F(1)=1 和 F(100) 的值。 但是对于「原始的」Binius,在已知的计算点进行检查是不安全的。有一些相当简单的方法可以将已知计算检查转换为未知计算检查,使用所谓的和检查协议;但是我们这里没有讲到这些。 查找协议,这是另一项最近被广泛使用的技术,它被用来制作超高效的证明系统。Binius 可以与许多应用程序的查找协议结合使用。 超越平方根验证时间。平方根是昂贵的:bit 的 Binius 证明 2 的 32 次方大约 11MB 长。你可以使用其他证明系统来弥补这个问题,以制作「Binius 证明的证明」,从而获得 Binius 证明的效率和较小的证明大小。另一种选择是更复杂的 FRI- binius 协议,它创建了一个多对数大小的证明 ( 就像普通的 FRI)。 Binius 是如何影响「SNARK 友好」的。基本的总结是,如果你使用 Binius,你不再需要关心如何使计算「算术友好」:「常规」哈希不再比传统的算术哈希更有效率,乘法模 2 的 32 次方 或模 2 的 256 次方 与乘法模相比不再是一件令人头疼的事情,等等。但这是一个复杂的话题。当一切都以二进制形式完成时,很多事情都会发生变化。
我希望在未来的几个月里,基于二进制字段的证明技术会有更多的改进。


