
解读ZKEVM:编译Solidity源码到LLVM IR系列(一)



作者:ZKSwap
零知识证明(ZKP)发展至今,大多数方案都是基于低级别表述语言实现的,例如 QAP、R1CS 或 Circuit。尽管 ZKP 不受语言限制,可以使用任何语言定义,但是高级语言所带来的生成证明的复杂度却是难以接受的。因此很多区块链技术团队开始使用新的 DSL 语言去编写业务逻辑,来实现复杂度较低的证明,但是这种模式却增加了用户编写合约的难度,因为大多数用户根本没有时间和精力学习 Rust、C++ 等语言。
Matter Labs 团队为了解决 ZKP 的图灵完备问题,引入了 ZINC 这门新的编写智能合约的语言。 然而该团队在 Youtube 上一段 ZKEVM 设计视频中曾公开表示 ZINC 目前并不是图灵完备的,缺乏循环、递归等内容。团队还表示,为了减少引入新的语言给开发者带来的学习成本,将尝试采用 Solidity-> YUL -> LLVM IR-> ZKEVM 的技术路线。
受该视频启发,本系列文章将与读者探讨使用 LLVM 编译器编译 Solidity /YUL字节码 到 R1CS 或 Circuit 的过程。尽管该方案后续可能发生重大变化,但是也是一次很好的学习机会。
第一篇 LLVM 介绍
概念
LLVM是模块化和可重用的编译器与工具链技术的集合, 经常被误认为是一个单纯的编译器,拿来跟 Clang 和 GCC 进行比较,实际上 Clang 也是仅仅作为 LLVM 项目的一部分单独发行的。以下是对这几个概念的详细介绍。
• LLVM :LLVM 和虚拟机技术没有关系。它的名字并不是一个缩写,而是 LLVM 项目的全称。LLVM 的目标是提供一个现代化的、基于 SSA 编译策略的、同时支持静态和动态编译任何编程语言的编译器架构。现在 LLVM 已经发展成为一个由多个子项目组成的总体项目,其中许多子项目已被广泛应用于学术研究、商业和开源项目中。LLVM 核心库提供了与编译器相关的支持,可以作为多种语言编译器的后端来使用。能够进行程序语言的编译期优化、链接优化、在线编译优化和代码生成。
• Clang :是 LLVM 的一个编译器前端,它目前支持 C, C++, Objective-C 以及 Objective-C++ 等编程语言。Clang 对源程序进行词法分析和语义分析,并将分析结果转换为 Abstract Syntax Tree(AST 抽象语法树) 和LLVM-IR,最后使用 LLVM 作为后端代码的生成器。
• GCC :GNU编译器套件(GNU Compiler Collection)包括C、C++、Objective-C、Java、Go语言的前端,也包括这些语言的库(如 libstdc++、libgcj 等)。GCC的开发初衷便是一款专为GNU操作系统设计的编译器。
传统编译器的三段式设计
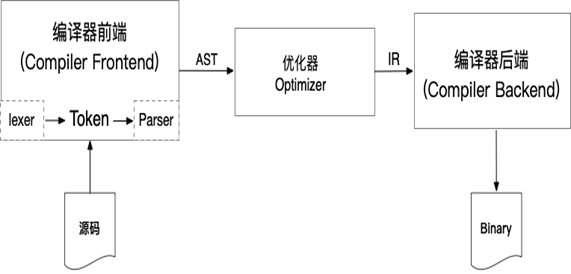
传统的静态编译器(例如大多数C编译器)采用三段式设计:前端、优化组件和后端。前端组件解析程序源代码,检查语法错误,生成一个基于语言特性的 AST(Abstract Syntax Tree)来表示输入代码,并提供给优化器。优化器会对AST数据进行相应的优化处理,以便最大程度的提升源代码的执行效率。优化后的中间表示代码(IR)会被送往后端程序。后端编译器会进行指令选择、寄存器分配等操作,最后将IR转化为相应平台的机器码。
优化器的作用是采用各种方式使代码运行得更快,例如删除死代码(DCE) 、常量折叠、传播优化等等策略。 后端(又叫代码生成器)将代码与任务指令一一对应起来。除了生成正确的代码以外,也要与机器设备的特性结合以保证生成代码的质量。通常编译器后端包括指令选择、寄存器分配和指令安排表等功能。JVM 也是采用这种模式,使用 Java 字节码作为前端与优化器的接口来实现的。
编译器的分段式架构使得开发分工更加明确。比如擅长编译器前端设计的开发人员,可以注重于编译器前端的设计,而不用考虑应该为后端优化器和编译器后端预留相应的资源以及进行什么样的配置。这也使得相关社区人员可以快速融入进来,实现自己力所能及的那部分。
三段式的结构设计是非常好的,但是因为各个编程语言的编译器和优化器的实现没有采用统一的 AST 和 IR 数据结构,导致对编译器链路的各个组成部分进行重用仍异常困难。
LLVM 编译器架构
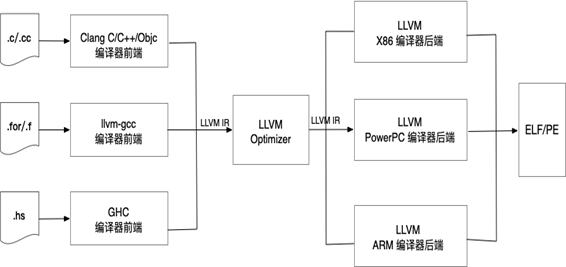
根据上述架构图我们可以看到 LLVM 编译器采用的是跟传统编译器相同的三段式架构,但存在明显的区别,即 LLVM 编译器架构的优化器输入和输出都是 LLVM-IR。 LLVM-IR 是 LLVM 框架构建的核心基础,它确立了IR的规范,使得其不同于传统的编译器前后端,将整体架构彻底拆分为三段式,方便开发人员进行分工。
总结 :我们经常使用的 Clang 只是一个 LLVM 编译器前端,它是狭义的 LLVM。 而 GCC 是一个完整的可执行文件,没有给其它语言的开发者提供代码重用的接口,因此复用静态库做静态分析或者代码重构时就会变得特别困难。而且脚本语言经常是通过动态解释嵌入到即将运行的大型应用程序中,这使得代码变得非常臃肿,复用其中的某一模块几乎不可能。 而 LLVM 作为后起之秀,既传承了三段式编译设计,又给开发者提供了可重用的编译前端和后端的接口,让开发者几乎不费力气就可以完成一个新语言的编译器前端。
LLVM 编译过程
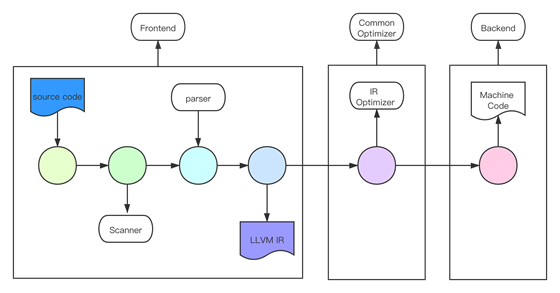
LLVM 编译过程涉及到前端、优化器、后端三部分的交互。具体过程如下:
-
Clang 读取源文件,并将源文件进行预处理。预处理的过程主要为:宏展开、导入头文件等。
-
词法分析器通过 Sanner 扫描处理过的源文件,生成 Token 序列,这个过程一般采用 Lex 完成。
-
语法分析在 Clang 中由 Parser 和 Sema 两个模块配合完成。根据定义好的语法(Grammar),对 Token 序列构成的输入文本进行分析并确定其语法结构。语法分析的过程会使用自顶向下或者自底向上的方式进行推导,最终形成AST(抽象语法树)。
-
CodeGen 负责将语法树从顶至下遍历,翻译成 LLVM IR。LLVM IR 既是 Frontend 的输出,也是 LLVM Backend 的输入。
-
通用优化器负责优化 LLVM IR, 可能会进行死代码删除(DCE) 、常量折叠、传播优化等过程。
-
最后 LLVM 后端根据 LLVM IR 生成特定平台可执行代码。
LLVM 常用工具链
为了方便介绍以下的工具链,我们编写一个简单的hello.c文件
#include<stdio.h>
int main() {
printf('Hello World!');
return 0;
}
• Clang 编译器
Clang 本身不属于 LLVM 命令行工具的一部分,但是因为它是基于 LLVM 工具链开发的,使得它拥有了其他类似编译器不具备的功能,使用 Clang 可以将高级语言的源文件编译为LLVM-IR中间代码
Clang -S -emit-llvm hello.c
在上面的命令中 参数 “-S” 指定编译器生成包含具有可读性汇编代码的目标文件; 参数 “-emit-llvm” 用于设置编译器以LLVM-IR的形式生成目标文件,该参数需要配合 “-S” 参数一起使用。当该命令执行完成后,会在当前目录生成一个名为 “hello.ll” 的文件, 文件名后缀为 “.ll”, 表示这是一个含有可读 LLVM-IR 代码的 ASCII 文本文件。
• LLVM-IR 解释器 - lli
通过 lli 命令,我们可以直接调用专门为 LLVM-IR 设计的即时解释器,解释器会逐行解释并执行目标文件内的 IR 代码。

• LLVM-IR 优化器 - opt
通过 opt 命令,我们可以直接在命令行中调用 LLVM 工具链提供的 IR 代码优化器对 LLVM-IR 代码优化,该优化器同时支持对可读文本以及二进制格式下的 LLVM-IR 代码进行优化,并且可以通过参数执行相应的优化策略。
优化策略比较多,这里不一一列举,只列举一些常用的策略
-mem2reg:该策略会将IR内的内存级变量引用提升为寄存器级变量引用
“-constprop” :该策略主要是用于 “常量传播优化”
“-dce” :该策略主要是用于删除死代码(无法执行到的代码)
opt -S -mem2reg -constprop -dce hello.ll
• LLVM 静态编译器 - llc
llc 是 LLVM 命令行工具提供的一个静态编译器。通过该编译器,可以将一个包含有 LLVM-IR 代码的 “.ll' 文件编译为以 “.s” 结尾的为特定平台架构的汇编代码文件。
llc hello.ll
执行完上述命令,会在当前目录生成一个 hello.s 的汇编文件,因为我的机器是 mac os 的,所以生成的汇编文件中会带有 mac os version 等字样
• LLVM 汇编器 - llvm-as
通过 llvm-as 命令行工具,可以将包含有可读文本格式的 LLVM-IR 文件转为二进制格式的 LLVM 比特码
llvm-as hello.ll
执行完上述命令,会在当前目录生成一个 hello.bc 的比特码文件,可以通过 hexdump 查看文件具体内容
• LLVM 符号表查看器 - llvm-nm
通过 llvm-nm 命令行工具,我们可以查看一个包含二进制 LLVM-IR 比特码的 “.bc” 文件内的符号表信息

上述命令中, “-A” 参数表示在输出结果中显示每个符号的来源文件名。 查看该输出可知在这个 LLVM 模块中存在两个符号,一个是内部名为 “main” 的符号,该符号对应着源码中的主函数,“T” 表示该函数是一个全局对象函数。“printf” 符号是引用外部标准库的函数, 所以用 “U”表示。
上面的实例中,我们生成了多个包含不同状态的 LLVM-IR 中间代码,以及面向特定底层平台架构的汇编代码,对于这些文件,我们都可以使用 Clang 将其编译为可执行的二进制文件。

总结
本文简单介绍了 LLVM 项目,让读者能够了解 LLVM 项目的整体架构,懂得通过改造 LLVM 编译器前端,可以适配多种高级编程语言,包括 Java、Rust、Solidity 等。 鉴于直接通过 Solidity 生成 LLVM IR 难度较大,且 Solidity 语法变更迅速,开发者可通过 Solidity 生成中间语言 YUL ,将 YUL 作为输入提供给 LLVM 前端生成 LLVM IR 字节码,即各种零知识证明需要的表示形式,最后在 ZKEVM 中执行。从理论上来讲这套逻辑没有任何问题,但是实际执行的工程难度还是非常大的,具体细节需要研究后再做定论。
下一篇我们将重点介绍 LLVM IR,敬请期待。
参考文献
[1].soll: https://github.com/second-state/SOLL [2].solang: https://github.com/hyperledger-labs/solang [3].Drevon G. SoK: Compiling programs for integration with multiple ZKP systems[J], 2020. [4].https://github.com/llvm/llvm-project

DeFi潮流新风口:从链上数据看跨链桥的发展新方向
总锁仓额突破131亿美元,9月独立地址总数超12万个
Bitwise 向美SEC提交比特币策略ETF申请,旨在投资比特币期货和其他金融产品
PANews 9月15日消息,根据一份公开的监管文件,资产管理公司Bitwise 下属部门 Bitwise Index Services 向美国证券交易委员会(SEC)递交了比特币期货交易所交易基金 ETF申请,新基金名为Bitwise Bitcoin Strategy ETF。旨在投资比特币期货和其他金融产品。该文件称:“该基金不会直接投资于比特币,虽然该基金主要通过间接投资于在 CFTC 注册的商品交易所交易的标准化、现金结算的比特币期货合约来获得比特币敞口,但它也可能投资于集合投资工具和加拿大上市的提供比特币敞口的基金”。文件显示,ETF 还可能投资于现金、美国政府证券或货币市场基金。US Bancorp Fund Services 将担任转账代理和管理人,而美国银行将担任托管方。据了解,美国证券交易委员会(SEC)至今还未批准任何比特币 ETF 基金。此外,美证监会主席 Gary Gensler 表示该机构更有可能批准比特币期货 ETF 而不是现货 ETF,因为期货 ETF 将投资于芝加哥商品交易所(CME)提供监管的比特币期货产品,而比特币现货则不受监管。来源链接
知情人士:因需求强烈,Coinbase计划发行的债券或增加至20亿美元
PANews 9月15日消息,有知情人士称,此前计划发行15亿美元债券的Coinbase会将交易规模提升至20亿美元,因为至少已经有70亿美元的订单涌入。其他知情人士表示,等额的7年期和10年期债券将分别以3.375%和3.625%的利率发行,低于最初讨论的借贷成本。彭博社表示,固定收益投资者对该产品的热捧,代表了加密货币不再是一个专属于风险资本的行业,因为养老基金和对冲基金在内的专注投资债务的投资者都希望参与到此次的投资中。此前根据 Coinbase 提交给美国证券交易委员会(SEC)文件显示,Coinbase 将通过私募发行 15 亿美元于 2028 年和 2031 年到期的有担保高级票据,这些票据将由 Coinbase 的全资子公司 Coinbase, Inc. 提供全额无条件担保。来源链接