技术入门 | 深入理解零知识证明算法之Zk-stark——FRI协议

收藏
分享
微信扫一扫
分享到朋友或朋友圈
前言
终于到了“理解零知识证明算法值Zk-stark”系列的收尾。在前面的三篇文章里,我们依次介绍了zk-stark算法的整体结构( https://www.8btc.com/article/512859 )、算法的第一部分:Arithmetization( https://www.8btc.com/article/516674 )、算法的第二部分:Low Degree Testing( https://www.8btc.com/article/522057 )。相信通过这几篇的阅读,大家能对zk-stark算法轮廓有了个整体的认知;在阅读的过程中,你可能会对文章中的某些语句或者图片的正确性发出疑问(确实有些内容需要更具体的介绍和说明,否则会产生误解),欢迎163邮箱留言交流(oceanjune512)。回顾第三篇的文章,我们已经讲到,为了确保证明者返回的满足多项式等式相等的值确实是基于有效的多项式计算得到,我们需要对多项式进行LDT测试;同时为了使验证者的复杂度达到最优,我们把原始多项式进行变换,变换后,证明者要证明的多项式仅仅是原始多项式的一半,不断重复这一过程,一直到多项式的度可以直接判断为止。这其实就是FRI协议的核心思想,下面,让我们来详细介绍FRI协议的过程。
FRI协议
也许,我们应该先说一下FRI协议是什么?FRI,即Fast RS IOPP,全称Fast Reed-Solomen Interactive Oracle Proofs of Proximity,是一种更有效的proximiary 测试方法,测试一个点的集合大部分是在一个度小于某个值的多项式上,能达到线性级的证明复杂度和对数级的验证复杂度。在我们正式介绍FRI协议之前,我们先看一个简单的场景。- 在有限域F上,存在一个乘法群L0,群的阶为2^n;
- 这时,证明者声称码字f0:L0-->F是满足RS[F,L0,ρ]编码参数的一个码字,即f0的大部分点在一个度d<ρ*2^n的多项式上P(x)上,这里ρ=2^(-R);
f0(x) = P(x) = P1(x^2) + x * P2(x^2) (1)
令Q(x, y) = P1(y) + x * P2(y),可以看出Q(x, y)关于x的度d < 2;关于y的度d < 1/2*ρ*2^n;此时,验证者随机选取一个值x0发送给证明者,然后令
f1(y) = Q(x0, y) = P1(y) + x0 * P2(y) (2)
对于f1(y),y=x^2,由于x取值范围是群1里的元素,因此x^(2^n) = 1 ==> (x^2)(2^(n-1)) = 1 ==> y(2^(n-1)) = 1。令y的作用域为群L1,则L1有以下属性:
- 群的阶为2^(n-1);
- 群L1的每个元素对应群L0的两个元素,即群L1的任意y,群L0都有两个x和(-x)mod F,满足x^2 mod F = y && (-x)^2mod F = y;
- 验证者分别从群L1和群L0选取三个点y,s0,s1满足 s0!=s1 && s0^2 = s1^2 = y
- 证明者返回f0(s0),f0(s1),f1(y)三个值
- 验证者根据f0(s0),f0(s1)插值出一个关于x的d<2的多项式g(x)
- 验证者验证g(s0) = f1(y),不相等,则失败
以上可知,对函数f1重复上述的过程,直到fr变成一个可以直接校验的度,就完成了整个测试验证过程。
下面,我们看一下FRI协议的具体内容,如图1所示:

- 验证者发送随机数x0
- 后证明者生成新函数f1,
- 进行一致性校验。
下面,先分别介绍Commit和Query协议里各参数和各个步骤的意义,然后总结一下相关的流程。
Commit:
-
Common input
- R RS编码比率
- i 循环次数索引,取值{0~r}
- r 循环次数 取值k0-R/η
- η空间映射参数 x-->x^(2^η)
- L0群的阶 2^k0
- RS[F,Li,ρ] 编码参数[ 有限域,作用域,编码比率 ]
- q0(x) = x^(2^η)(实际实现的定义,和图中不一致),L(i+1) = q0(Li),表示群Li到群L(i+1)的2^η --> 1映射
-
Prover input
- fi 第i次循环的函数输入
- Li 第i次循环的群,阶位2^(n-i)
- RSi fi对应的编码参数
-
LOOP i <= r
-
1
- xi 验证者发送的随机数
-
2
- Sy 群L(i+1)的每一个元素对应于群Li的元素的集合
- f(i+1)(y) 计算f(i+1)在群L(i+1)上的所有取值
-
3 i==r
- 定义fr 第2步的输出
- 插值出P(x)
- d是多项式P(x)的度
- 保存d+1个多项式P(x)的系数 a0~ad
- Commit 阶段终止
-
4 i < r
- 定义f(i+1) 按照第2步的计算方式
- 保存f(i+1)的值,在群L(i+1)
- 进入下一步循环
-
1
-
verifier input
- R /η /Li /RSi /xi /fi /P(x) 见Commit
- l query次数
-
重构fr
- 获取a0~ad,重构P`(x)
- 计算P`(x)在群Lr上的所有取值,并赋值给fr,注fr满足RSr
-
repeat l times
-
i = {0~r-1}
- Si 满足s(i+1) = q0(x)的x的集合
-
i = {0~r-1}
- 在Si上,插值出Pi(x)
-
round consistency check i = {0~r-1}
- f(i+1)(s(i+1)) = Pi(xi)
- 都成功,则验证通过
-
i = {0~r-1}
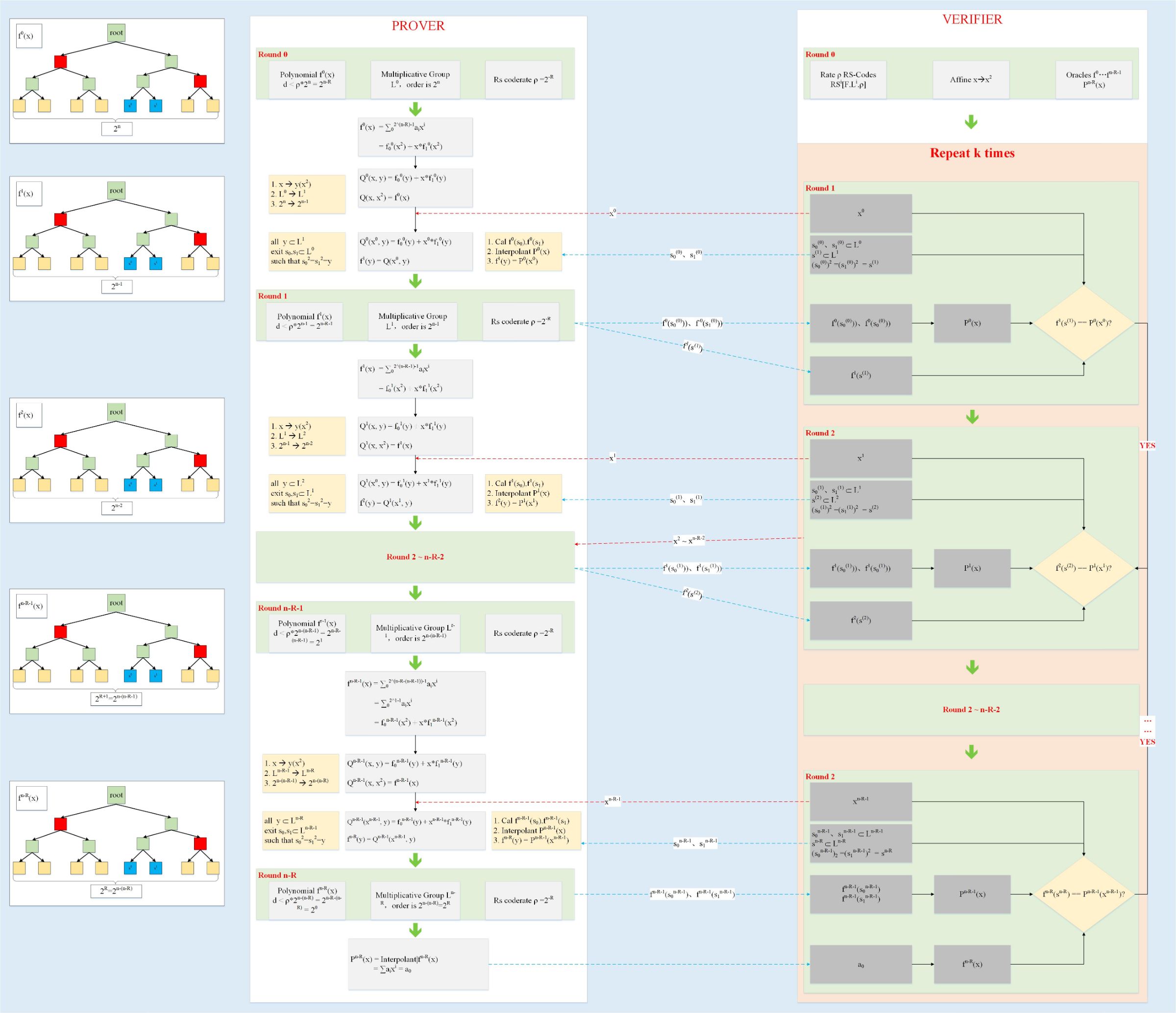
- 针对每一轮的一致性的校验,确保了原始多项式f0的确满足d < ρ*2^n
- 上述协议重复l次,可以大大降低作恶者成功的概率
总结
以上就是FRI协议的具体过程,可以看出,验证复杂度满足对数关系r = Log2(ρ*2^n)。算法保证了,当且仅当原始多项式f0是小于ρ*2^n时,所有的round consistency 校验才会通过。真正的实现可能略有差别,具体的可以参考DEEP-FRI论文,相对于FRI,DEEP-FRI在保持证明和验证的最优复杂度的同时,提高了系统的可靠性。结合本系列的前三篇的文章,总结ZK-STARK的算法如下:
- 算法分为两部分:算术化和LDT
- 算术化把问题转换位多项式相等以及多项式的LDT问题
- LDT阶段使用FRI协议,保证线性级的证明复杂度和对数级的验证复杂度
- 零知识属性保证验证者不能访问轨迹多项式里的点,轨迹多项式里保存着隐私值
- 同时为了保证零知识属性,需要对轨迹多项式附加数行随机值,由验证者和证明者协商确定
- 整个过程,不需要第三方的CRS
- 整个过程,不依赖任何数学难题
附录
- 官方FRI的简单介绍 https://medium.com/starkware/low-degree-testing-f7614f5172db
- FRI paper https://eccc.weizmann.ac.il/report/2017/134/
- DEEP-FRI paper chrome-extension://cdonnmffkdaoajfknoeeecmchibpmkmg/assets/pdf/web/viewer.html?file=https%3A%2F%2Farxiv.org%2Fpdf%2F1903.12243.pdf
- Reed-Solomen WIKI https://en.wikipedia.org/wiki/Reed%E2%80%93Solomon_error_correction
免责声明:本文版权归原作者所有,不代表MyToken(www.mytokencap.com)观点和立场;如有关于内容、版权等问题,请与我们联系。


