


原文作者:Egor Shulgin, Gonka 协议
AI技术的迅猛发展已将其训练过程推向了任何单一物理位置的极限,这迫使研究人员面对一个根本性挑战:如何协调分布在不同大洲(而非同一机房走廊内)的数千个处理器?答案在于更高效的算法——那些通过减少通信来工作的算法。这一转变,由联邦优化领域的突破所驱动,并最终结晶于DiLoCo等框架,使得组织能够通过标准互联网连接训练拥有数十亿参数的模型,为大规模协作式AI开发开启了新的可能。
1. 起点:数据中心内的分布式训练
现代AI训练本质上是分布式的。业界普遍观察到,扩大数据、参数和计算规模能显著提升模型性能,这使得在单台机器上训练基础模型(参数达数十亿)成为不可能。行业的默认解决方案是“集中式分布式”模式:在单一地点建设容纳数千个GPU的专用数据中心,并通过超高速网络(如英伟达的NVLink或InfiniBand)互连。这些专用互联技术的速度比标准网络高出几个数量级,使得所有GPU能够作为一个 cohesive 的整体系统运行。
在此环境下,最常见的训练策略是数据并行,即将数据集拆分到多个GPU上。(也存在其他方法,如流水线并行或张量并行,它们将模型本身拆分到多个GPU上,这对于训练最大的模型是必需的,尽管实现起来更复杂。)以下展示了使用小批量随机梯度下降(SGD)的一个训练步骤是如何工作的(同样的原理也适用于Adam优化器):
- 复制与分发: 将模型副本加载到每个GPU上。将训练数据分割成小批量。
- 并行计算: 每个GPU独立处理一个不同的小批量,并计算**梯度**——即调整模型参数的方向。
- 同步与聚合: 所有GPU暂停工作,共享它们的梯度,并将其平均,以产生一个单一的、统一的更新量。
- 更新: 将这个平均后的更新量应用到每个GPU的模型副本上,确保所有副本保持完全一致。
- 重复: 移至下一个小批量,重新开始。
本质上,这是一个并行计算与强制同步不断循环的过程。在每一步训练之后都会发生的持续通信,只有在数据中心内部昂贵、高速的连接下才可行。这种对频繁同步的依赖,是集中式分布式训练的典型特征。它在离开数据中心这个“温室”之前,运行得非常完美。
2. 撞上南墙:巨大的通信瓶颈
为了训练最大的模型,组织现在必须以惊人的规模建设基础设施,通常需要在不同城市或大洲建立多个数据中心。这种地理上的分隔造成了一个巨大的障碍。那种在数据中心内部运行良好的、逐步同步的算法方法,当被拉伸到全球范围时,就失效了。
问题在于网络速度。在数据中心内部,InfiniBand的数据传输速度可达400 Gb/s或更高。而连接遥远数据中心的广域网(WAN),其速度通常接近1 Gbps。这是几个数量级的性能差距,其根源在于距离和成本的基本限制。小批量SGD所假设的近乎瞬时的通信,与这一现实格格不入。
这种差异造成了严重的瓶颈。当模型参数必须在每一步之后都进行同步时,强大的GPU大部分时间都处于闲置状态,等待数据缓慢地爬过低速网络。结果是:AI社区无法利用全球范围内分布的海量计算资源——从企业服务器到消费级硬件——因为现有算法需要高速、集中式的网络。这代表着一个巨大且尚未开发的算力宝库。
3. 算法转变:联邦优化
如果频繁通信是问题所在,那么解决方案就是减少通信。这一简单的见解奠定了一场算法转变的基础,它借鉴了联邦学习的技术——该领域最初专注于在终端设备(如手机)上的去中心化数据上训练模型,同时保护隐私。其核心算法 联邦平均 (FedAvg)表明,通过允许每个设备在本地执行多次训练步骤后再发送更新,可以将所需的通信轮数减少几个数量级。
研究人员意识到,在同步间隔之间做更多独立工作这一原则,是解决地理分布式设置中性能瓶颈的完美方案。这导致了 联邦优化 (FedOpt)框架的出现,它采用双优化器方法,将本地计算与全局通信解耦。
该框架使用两种不同的优化器运作:
- 内部优化器(如标准SGD)在每个机器上运行,在其本地数据切片上执行多次独立的训练步骤。每个模型副本都自行取得显著进展。
- 外部优化器处理不频繁的全局同步。在经过多次本地步骤后,每个工作节点计算其模型参数的总变化量。这些变化被聚合起来,外部优化器利用这个平均后的更新量来调整下一周期的全局模型。
这种双优化器架构从根本上改变了训练的动态过程。它不再是所有节点之间频繁的、逐步的通信,而变成了一系列延长的、独立的计算期,之后跟随一个单一的聚合更新。这场源于隐私研究的算法转变,为实现低速网络上的训练提供了至关重要的突破。问题是:它能用于大规模语言模型吗?
以下为联邦优化框架示意图:本地训练与周期性全局同步
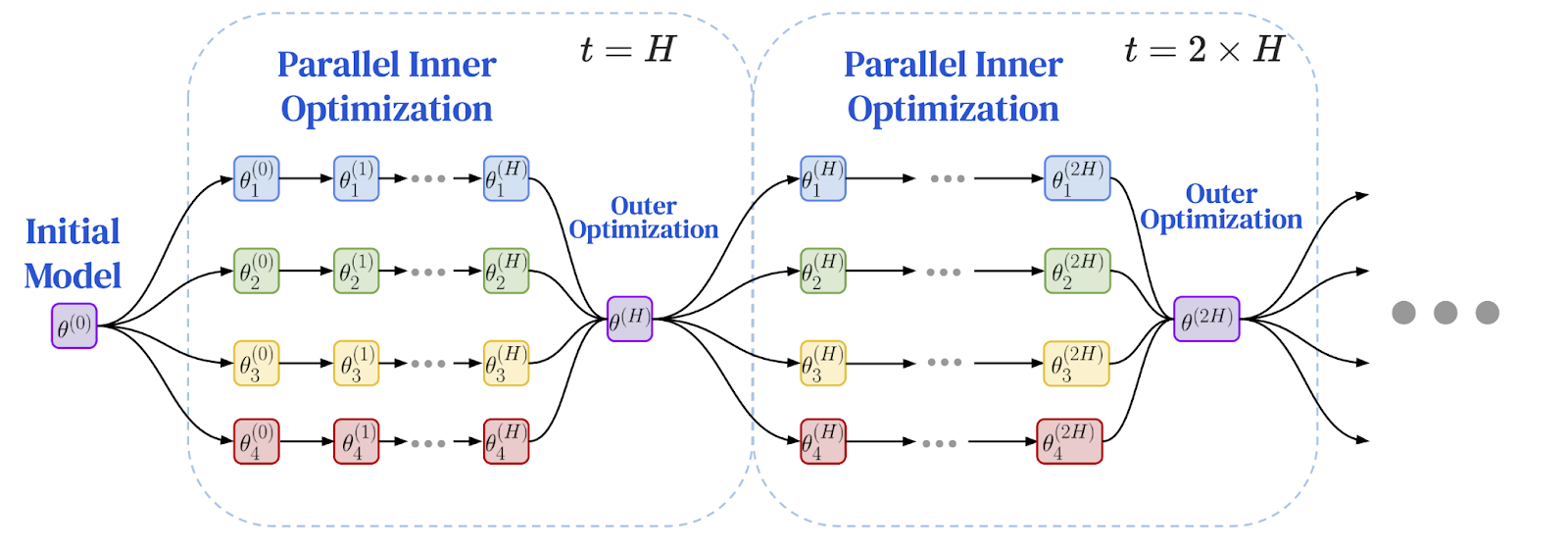
图片来源:Charles, Z., et al. (2025). "Communication-Efficient Language Model Training Scales Reliably and Robustly: Scaling Laws for DiLoCo." arXiv:2503.09799
4. 突破性进展:DiLoCo证明其大规模可行性
答案以 DiLoCo(分布式低通信) 算法的形式出现,它证明了联邦优化对于大语言模型的实际可行性。DiLoCo提供了一套具体的、经过精心调优的方案,用于在低速网络上训练现代Transformer模型:
- 内部优化器: AdamW,这是用于大语言模型的尖端优化器,在每个工作节点上运行多次本地训练步骤。
- 外部优化器: Nesterov动量,一种强大且易于理解的算法,处理不频繁的全局更新。
最初的实验表明,DiLoCo能够匹配完全同步的数据中心训练的性能,同时将节点间的通信量减少高达500倍。这是通过互联网训练巨型模型可行的实践性证明。
这一突破迅速获得了关注。开源实现 OpenDiLoCo 复现了原始结果,并利用Hivemind库将该算法集成到一个真正的点对点框架中,使得该技术更易于使用。这一势头最终促成了 PrimeIntellect 、 Nous Research 和 FlowerLabs 等组织成功进行的大规模预训练,它们展示了使用低通信算法通过互联网成功预训练了数十亿参数模型。这些开创性的努力将DiLoCo式训练从一个有前途的研究论文,转变为在中心化提供商之外构建基础模型的已验证方法。
5. 前沿探索:先进技术与未来研究
DiLoCo的成功激发了新一轮的研究热潮,专注于进一步提升效率和规模。使该方法走向成熟的关键一步是 DiLoCo缩放定律 的发展,该定律确立了DiLoCo的性能能够随着模型规模的增长而可预测且稳健地缩放。这些缩放定律预测,随着模型变得更大,一个经过良好调优的DiLoCo可以在固定的计算预算下,性能超越传统的数据并行训练,同时使用的带宽少几个数量级。
为了处理1000亿参数以上规模的模型,研究人员通过像 DiLoCoX 这样的技术扩展了DiLoCo的设计,它将双优化器方法与流水线并行相结合。DiLoCoX使得在标准的1 Gbps网络上预训练一个1070亿参数模型成为可能。进一步的改进包括 流式DiLoCo (它重叠通信和计算以隐藏网络延迟)和 异步方法 (防止单个慢速节点成为整个系统的瓶颈)。
创新也发生在算法核心层面。对像Muon这样的新型内部优化器的研究催生了 MuLoCo ,这是一个变体,允许将模型更新压缩到2比特且性能损失可忽略不计,从而实现了数据传输量减少8倍。或许最雄心勃勃的研究方向是互联网上的模型并行,即将模型本身拆分到不同的机器上。该领域的早期研究,例如 SWARM并行 ,开发了将模型层分布到由低速网络连接的异构且不可靠设备上的容错方法。基于这些概念,像 Pluralis Research 这样的团队已经证明了训练数十亿参数模型的可能性,其中不同的层托管在完全处于不同地理位置的GPU上,这为在仅由标准互联网连接的分布式消费级硬件上训练模型打开了大门。
6. 信任挑战:开放网络中的治理
随着训练从受控的数据中心转向开放、无需许可的网络,一个根本性问题浮现了:信任。在一个没有中央权威的真正去中心化系统中,参与者如何验证他们从其他人那里收到的更新是合法的?如何防止恶意参与者毒化模型,或者懒惰的参与者为他们从未完成的工作索取奖励?这个治理问题是最后的障碍。
一道防线是 拜占庭容错 ——一个来自分布式计算的概念,旨在设计即使部分参与者出现故障或主动恶意行为也能正常运作的系统。在集中式系统中,服务器可以应用鲁棒的聚合规则来丢弃恶意更新。这在点对点环境中更难实现,因为那里没有中央聚合器。取而代之的是,每个诚实节点必须评估来自其邻居的更新,并决定信任哪些、丢弃哪些。
另一种方法涉及 密码学技术 ,用验证替代信任。一个早期的想法是 学习证明 (Proof-of-Learning),提议参与者记录训练检查点以证明他们投入了必要的计算。其他技术如零知识证明(ZKPs)允许工作节点证明他们正确执行了所需的训练步骤,而无需透露底层数据,尽管其当前的计算开销对于验证当今大规模基础模型的训练仍是一个挑战。
前瞻:一个新AI范式的黎明
从高墙耸立的数据中心到开放的互联网,这段旅程标志着人工智能创建方式发生了深刻转变。我们始于集中式训练的物理极限,那时进步取决于对昂贵的、同地协作硬件的获取。这导致了通信瓶颈,一堵使得在分布式网络上训练巨型模型不切实际的墙。然而,这堵墙并非被更快的线缆打破,而是被更高效的算法所攻克。
这场植根于联邦优化并由DiLoCo具体化的算法转变,证明了减少通信频率是关键。这一突破正被各种技术迅速推进:建立缩放定律、重叠通信、探索新型优化器,乃至在互联网上并行化模型本身。由多元化的研究者和公司生态系统成功预训练数十亿参数模型,正是这种新范式力量的明证。
随着信任挑战通过鲁棒防御和密码学验证得到解决,道路正在变得清晰。去中心化训练正在从一个工程解决方案,演变为一个更开放、协作和可访问的AI未来的基础支柱。它预示着一个世界,在那里,构建强大模型的能力不再局限于少数科技巨头,而是分布在全球,释放所有人的集体计算力量和智慧。
参考文献
McMahan, H. B., et al. (2017). Communication-Efficient Learning of Deep Networks from Decentralized Data . International Conference on Artificial Intelligence and Statistics (AISTATS).
Reddi, S., et al. (2021). Adaptive Federated Optimization . International Conference on Learning Representations (ICLR).
Jia, H., et al. (2021). Proof-of-Learning: Definitions and Practice . IEEE Symposium on Security and Privacy.
Ryabinin, Max, et al. (2023). Swarm parallelism: Training large models can be surprisingly communication-efficient . International Conference on Machine Learning (ICML).
Douillard, A., et al. (2023). DiLoCo: Distributed Low-Communication Training of Language Models .
Jaghouar, S., Ong, J. M., & Hagemann, J. (2024). OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training .
Jaghouar, S., et al. (2024). Decentralized Training of Foundation Models: A Case Study with INTELLECT-1 .
Liu, B., et al. (2024). Asynchronous Local-SGD Training for Language Modeling .
Charles, Z., et al. (2025). Communication-Efficient Language Model Training Scales Reliably and Robustly: Scaling Laws for DiLoCo .
Douillard, A., et al. (2025). Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch .
Psyche Team. (2025). Democratizing AI: The Psyche Network Architecture . Nous Research Blog.
Qi, J., et al. (2025). DiLoCoX: A Low-Communication Large-Scale Training Framework for Decentralized Cluster .
Sani, L., et al. (2025). Photon: Federated LLM Pre-Training . Proceedings of the Conference on Machine Learning and Systems (MLSys).
Thérien, B., et al. (2025). MuLoCo: Muon is a practical inner optimizer for DiLoCo .
Long, A., et al. (2025). Protocol Models: Scaling Decentralized Training with Communication-Efficient Model Parallelism .
原文链接


