引入AI,新推出的LLM计划会成为Dune的杀手锏吗?



近日,加密数据查询网站 Dune 宣布更新其 LLM( 大型语言模型,Large language model)路线图,首期上线 GPT-4 支持的查询解释(Query Explanations)功能,后期将会逐渐增加更多功能,比如自然语言查询(Natural Language Querying)、SQL 语句转义(Query Translations)和优化搜索等。
不同于其他数据分析网站付费查询商业化路线,Dune 在上线后始终对普通用户免费开放,因此在上轮的牛市周期沉淀了足够多的用户量,而 LLM 的加入,则有望使其沉淀的数据查询语句、看板转化为实际的杀手锏,并且引导普通用户加入创作者行列。
Dune 的数据查询鸿沟
得益于区块链数据的公开性和透明度,任何人都可直接访问区块链数据,但是原始数据(Raw Data)往往难以辨认,非专业程序员很难看懂其含义,但是其上的数据蕴藏着巨大的经济价值,因此各类数据分析工具便应运而生,为各类分析师、研究员和普通散户提供间接访问和深度分析的工具。

Dune 在其中最为引人注目,因为其提供了真正自由且强大的分析工具,任何人都可通过 SQL 语句进行对数据的查询、分享和展示,甚至部分项目直接选择 Dune 作为官方信息展示平台。
但是 Dune 的 SQL 查询功能,表面看是 UGC 模式,平等的赋予每一个用户权限去执行查询任务,但实际上 Dune 采纳的 SQL 模式存在两个问题,其一是门槛过高,SQL 是(结构化查询语言,Structured Query Language)的简写,比如查询 Uniswap 上以 DAI 作为交易对的数量,仅仅需要 5 行代码即可完成。但是一旦执行查询的逻辑变得复杂,其代码量可能会大幅增加,非专业程序员很难自行写出,这导致大量用户只能成为看客。

例如,官方进行简化后的"nft.trades "查询流程,包含了近 20 万行的 SQL 语句转换、 10 万行的测试代码,并且由 55 个社区成员参与其中,单个用户无法处理如此大规模的任务。

其二是 Dune 的V1和V2版本的之间支持的 SQL 标准并不统一,V1和V2分别使用的 Po stgreSQL 和 Spark SQL,后续计划由 Dune SQL 完成统一。
在本次升级 LLM 功能之前,Dune 已经在准备统一查询引擎,计划在今年 7 月份之后全部迁移至 Dune SQL,以保证产品逻辑的统一性。更新后的 Dune SQL 是基于开源查询引擎 Trino 的实现,Dune 对其进行优化,以适配 Dune 自身的需求,与流行的 Spark SQL 并无本质上的差异,更多是在具体函数和语法上的改进。比如 Dune SQL 提供了更多的运算符,方便快速对日期和时间进行计算,以及对管理权限进行限制,所有涉及对原始数据本身的删除、更新等操作均无法执行,以保证数据的 安全 性。
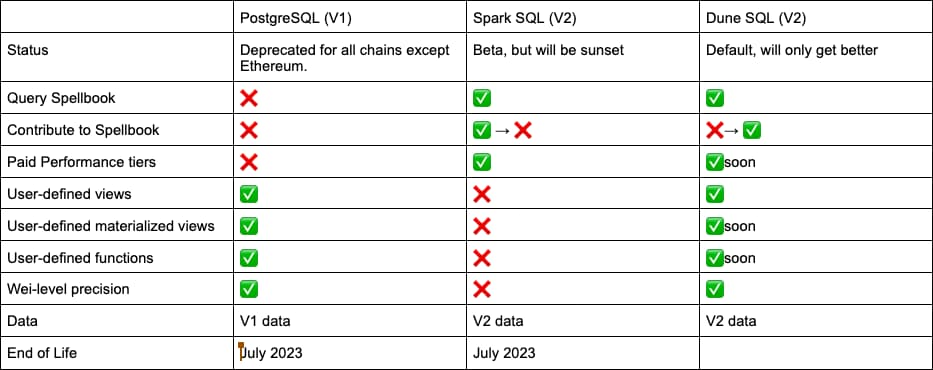
但是 SQL 查询门槛过高的问题,依旧无法通过更改 SQL 范式得到解决,这意味着大多数用户和程序员都要去适应新的语法格式,比如说针对具体的查询语句,新用户和程序员都要去适应。而对自动化工具的需求,不仅对于普通用户具备现实意义,对不熟悉新语法的程序员也大有裨益。
实际上,在迁移 Dune SQL 路线图中,Dune 已经在尝试实验自动化工具,可以将不同的语法格式统一转化为 Dune SQL 语句,而在 GPT-4 使用 LLM 显示人机交互方面的威力后,Dune 也顺势推出自己的 LLM 计划。
LLM:解锁普通用户的参与感
Dune 的典型流程是解构链上数据,专业用户通过 SQL 执行查询,随后将看板(Dashboard)分享给有需要的用户。在这个流程中,最关键的是执行查询,而大多数用户因为缺乏代码知识而无法使用查询功能。
而在引入查询解释功能后,上述流程发生一些微调,在专业用户写的 SQL 查询界面,会出现解释页面,以自然语言的格式直观地告诉查看用户代码的具体作用,相当于给 SQL 查询添加一个解释说明的补丁,并不会改变当前的工作流程,这也是团队在吸取合并 SQL 语句时的教训,即降低对用户既有习惯的干扰,而是尽可能在现有流程优化体验。
在 LLM 加入后,一定程度上抹去了专业用户和普通用户的能力差异。借助 GPT-4 对代码的理解能力,可以让普通用户直观的理解查询语句的作用,而无需掌握 SQL 知识。在此功能引入前,用户只能被动的在看板页面阅读图表,而在引入查询解释功能后,普通用户也可以理解 SQL 代码是发挥作用的具体含义。
比如说 Alice 想要查询 LayerZero 交易的相关信息,那么她可以直接找到 Bob 已经制作好的 Dune 看板,可以发现 49.4% 的用户都集中在 1 次,那么 Alice 有理由推断说明这是为了潜在的经济刺激而进行的虚假交易,但是无法一锤定音,因此 Alice 决定去翻阅代码检查结论是否可靠。

但是 Alice 发现虽然结果只有 5 行数据,但是查询代码足足有 150 行,Alice 的 SQL 水平不足以确认每个语句的正确性,而此时查询解释功能则会“翻译”代码的具体说明,如图所示,查询分成了 3 个部分:收集数据涵盖了 Arbitrum 、 Avalanche 、 BNB 、Ethereum、 Optimism 、 Polygon 和 Fantom 等多条链,并且第二部分是计算每个用户(`sender`)的交易数量。第三部是针对数量设置阈值对用户进行分类: 1 Tx', '2 ~ 5 Tx', '5 ~ 10 Tx', '10 ~ 20 Tx', 和'>= 20 Tx' 。
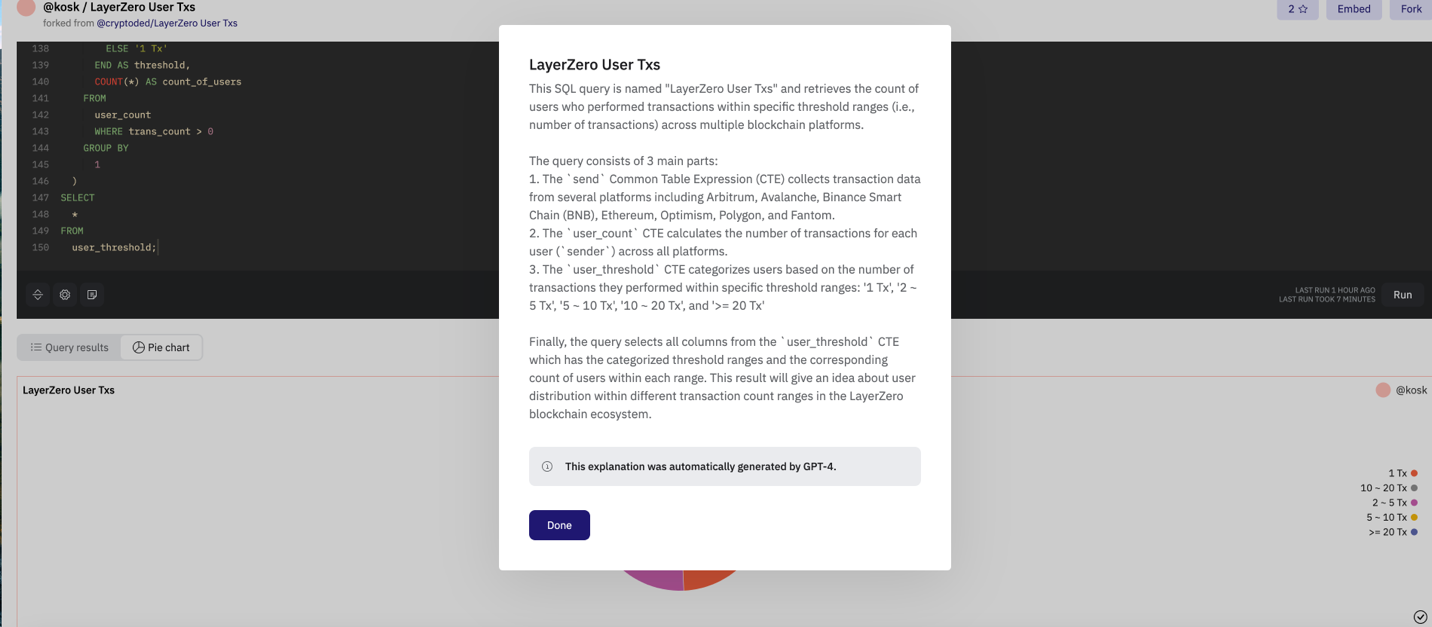
那么此时 Alice 可以在不理解 Bob 写的代码含义基础上去进行分析和判断。本质上,查询解释的功能相当于给代码和人类之间进行了一次转义和翻译,那么反过来,也可以将人类语言翻译成 SQL 语句,在 LLM 加持下,得益于 Dune 攒下的海量查询语句数据,这并不难实现。
自然语言查询(Natural Language Querying)就是 Dune 后续 LLM 改进的重要方向。自然语言查询可以让用户以传达指令的方式去执行图表生成任务,这比使用 SQL 语句、拖曳生成等模式更为符合普通人的思维方式,免去对实现细节的关注。
并且,自然语言查询并不是对专业用户,如分析师群体的替代功能,而是一种补强,现存的 Dune 有将近 70 万个图表,相当一部分的分析任务是重叠和冲突的,而使用自然语言查询,也有助于系统去理解图表之间的关联,从而进一步提升整个分析工作的效率。
在 LLM 加入后,现存图表、SpellBook 和文档数据也将被重新整合,效仿 OpenAI 的聊天机器人,Dune 也会开发对话机器人,帮助用户以更简易的方式去理解和利用现存的知识体系,而不需要受到不相关信息的干扰。
比如,Alice 可以将上述查询 LayerZero 用户交易量分布的情况逆置,先用英语发出查询指令,并且交代好每一步的工作流程,随后 Dune 会帮助 Alice 写好 150 行代码,随后生成图表。
结语:人人都 能当 数据分析师
Dune 的目标并不是建立一个单纯的链上数据分析平台,而是希望打造一个可以使信息自由流动的数据管道,允许用户抓取、转换、管理、查询、可视化以及利用数据去采取行动。
数据流动的前提是必须进行模块化,可任意组合和配置,最终建造社区共享的数据集,而不是集中在复杂的 SQL 语句或者付费 API 之内,最终达到人人都可和数据进行交互的平权图景。
概要而言,Dune 的 LLM 计划是“翻译”和助手,目标是让普通用户读懂数据所代表的一切,不仅是最终结果的展示,而是深入到生成过程之中,最终人人都可进行链上数据分析。
Bitcoin Sees Influx Of New Capital: First-Time Buyers Add 140,000 BTC
On-chain data shows the supply held by new Bitcoin buyers has seen a jump recently, a sign that the ...

Neurolov and Deepbook AI Build DeFi Browser Backed by Distributed GPUs
According to Neurolov, this latest partnership with Deepbook AI allows users to enjoy smooth DeFi ex...

BTC Price Action: Michaël van de Poppe Eyes $110K Entry Zone
The crypto analyst, Michaël van de Poppe, published an essential update regarding altcoins. As $BTC ...